Table of contents
Wie richtiger Datenschutz vor Willkür schützt
Die Augsburger Allgemeine betreibt ein Forum, in dem Menschen Zeitungsartikel diskutieren können. In einem dieser Artikel ging es um das politische Wirken von Ordnungsreferent Volker Ullrich, das einer der Benutzer wie folgt kommentiert hatte:
Dieser Ullrich verbietet sogar erwachsenen Männern ihr Feierabendbier ab 20.00 Uhr, indem er geltendes Recht beugt und Betreiber massiv bedroht!
Aufgrund dieses Kommentars fühlte sich Ullrich beleidigt und in seiner Ehre verletzt, was in Deutschland - so traurig das sein mag - rechtlich verfolgbar ist. Er erstattete Anzeige und das Amtsgericht Augsburg beauftragte die Polizei mit einer Durchsuchung der Redaktionsräume um an die Daten des Nutzers zu kommen, die nachher die Daten freiwillig herausgerückt hatten. So weit, so bekannt.
Nun wird vielerorts darauf hingewiesen, dass keineswegs der Politiker Ullrich einen Fehler gemacht hätte, indem er die Sache zur Anzeige gebracht hat, sondern das Amtsgericht Augsburg, das aufgrund dieser Anzeige eine Durchsuchung bei einem verfassungsrechtlich geschützen Organ in die Wege geleitet hatte.
Diese Ansicht ist in zweierlei Hinsicht falsch. Erstens ist es tatsächlich Ulrichs Anzeige, die den Stein ins Rollen brachte. Insofern ist er als der Verursacher einer Willkürjustiz zu betrachten. Er mag formaljuristisch im Recht gewesen sein (d.h. die Anzeige zu erstatten! Ob die Anzeige gerechtfertigt war, darf zu bezweifeln sein). Er hätte, als Person des öffentlichen Interesses, aber auch einfach auf eine Verfolgung verzichten können. Ein Schaden wäre ihm nicht entstanden. Niemand hätte von dem Forenbeitrag überhaupt Notiz genommen. Andererseits ist es auch nicht der Fehler des Amtsgerichts Augsburg, das den Durchsuchungsbeschluss ausgestellt hatte. Denn auch dies geschah im Rahmen geltenden Rechts. Hinzu kommt, dass wir in Deutschland bekanntermaßen keine unabhängige Justiz haben, sondern dass diese weisungsgebunden handelt. Diese Weisungen erhält die Justiz bei uns von der Exekutive, deren Mitglied Ullrich ist. Dieser Zustand ist für eine Demokratie zwar eine völlige Katastrophe, aber es ist eben so. Und insofern kann man einem Amtsgericht auch nicht dahingehend Vorwürfe machen.
Der eigentliche Adressat von Vorwürfen sollte die Augsburger Allgemeine sein. Der Fehler, den das Blatt gemacht hat, ist sehr einfach zu beschreiben: Verletzung des Datenschutzes. Wenn man als Presseorgan ein öffentliches Forum betreibt und den Benutzern nicht die Verwendung ihres Klarnamens vorschreibt, dann hat dieses Presseorgan auch dafür zu sorgen, dass das tatsächlich der Fall ist. Konkret heisst das, dass in einem solchen Setup keine IP-Adressen der Forenbenutzer geloggt werden dürfen, keine Emailadressen oder sonstige Daten, die ein Forenposting mit einer real existierenden Person in Verbindung bringen könnten. Davon abgesehen, ist es der Zeitung ohnehin verboten, solcherlei Daten aufzuzeichnen, da diese für die Zeitung nicht abrechnungsrelevant sind.
Hätte sich die Augsburger Allgemeine an diese einfachen Grundsätze gehalten, wäre sie gar nicht erst in die Lage geraten, die Daten eines Forennutzers an die Polizei herausgeben zu müssen, um eine Redaktionsdurchsuchung zu vermeiden. Vielmehr hätte sie die Herausgabe der Daten weiter verweigern können unter Verweis auf die öffentlichen Datenschutzrichtlinien. Hätte das Amtsgericht dann trotzdem auf einer Durchsuchung bestanden, um Daten zu finden, die es gar nicht gibt, DANN wäre das nicht nur Rechtsbeugung, sondern Rechtsbruch gewesen und die Zeitung hätte in jedem Fall sämtliche nachfolgenden Prozesse gegen das AG Augsburg und Ullrich mit Pauken und Trompeten gewonnen. Sie hätte als leuchtendes Beispiel für die Verteidigung der Pressefreiheit und Meinungsfreiheit dastehen können.
Aber so? In meinen Augen ist die Augsburger Allgemeine ein nicht vertrauenswürdiges Presseorgan. Sie denunzieren Dritte ohne Not an den Staat. Mit "Ohne Not" meine ich, dass dem Vorgang ja keine gerichtliche Verurteilung vorausgegangen ist. Und nur dann ist ein Bürger eines Verbrechens/Vergehens schuldig, bis dahin hat er als unschuldig zu gelten und ein Presseorgan sollte das verteidigen, anstatt es ad absurdum zu führen.
Sagen wir, ich wäre ein potentieller Informant und würde ein Presseorgan suchen, dem ich brisante Informationen über einen gewissen Herrn Ullrich in Augsburg zuspielen will. Wem würde ich wohl diese Informationen anvertrauen? Der Augsburger Allgemeinen? Auf allergarkeinen Fall! Die würden meinen Namen, Adresse, Telefonnummer und Email in ihrer Datenbank speichern und jedem dahergelaufenen Staatsvertreter aushändigen, der sie nur laut genug bedroht.
Dieses Einknicken der deutschen Presse gegenüber dem deutschen Staat, dessen Kontrolleur sie eigentlich zu sein hat, ist der Grund für ihren Niedergang. Und nicht irgendwelche Raubkopierer oder Suchmaschinen, denen sie mit ihrem Leistungsschutzrecht zu leibe rücken wollen. Und wenn ich mir das Verhalten der Augsburger Allgemeinen anschaue, muss ich sagen: es ist gut, dass eine solche Presse den Bach runtergeht.
Update 2013-03-21:
Und es kam, wie es kommen musste: Die Aktion war illegal, hat nun das Landgericht geurteilt. Die schlechte Nachricht: das Gericht hat sich nicht der Ansicht angeschlossen, ein Forenuser eines Presseorgans falle unter Zeugnisverweigerungsrecht. Das ist bitter und enttäuschend, aber ich habe nichts anderes erwartet in diesem Staat.Update 2013-02-13:
Thomas Stadler kommt zum gleichen Ergebnis:Wenn man dem Betreiber oder Mitarbeiter von Meinungsforen kein Zeugnisverweigerungsrecht zubilligen will, dann wird man ihnen künftig raten müssen, von der gesetzlichen Möglichkeit, Kommentare und Bewertungen anonym abgeben zu lassen, Gebrauch zu machen. Denn wer keine Informationen über die Person des Verfassers eines Kommentars hat, kann auch als Zeuge dazu keine Angaben machen.
↷ 30.01.2013 🠶 #gesellschaft ⤒
Sensorita - Hutschienen LCD Display für Sensoranzeige
Heute wollte ich eigentlich meinen Sensorcontroller für das neue Terrarium zusammenbauen. Geplant war, in ein leeres Hutschienengehäuse den Arduino Micro, alle Steckeranschlüsse, das LCD-Display und 2 Buttons unterzubringen. Aber ich hab es einfach nicht hingekriegt, den ganzen Kram da so reinzukriegen, dass ich ihn im Fall der Fälle auch wieder herausbekomme. Tja. Somit habe ich umdisponiert und nur das LCD-Display und die beiden Buttons eingebaut. Auf die Leiterplatte habe ich auch die Pulldown-Widerstände für die Buttons und die Widerstände für den LCD-Anschluss drauf. Das Poti für die Kontrasteinstellung hab ich auch mit unterbringen können. Dann habe ich einen standardmässigen JST Stecker an 20cm Kabeln herausgeführt. Den Arduino mit den Sensoranschlüssen werde ich dann auf der Rückseite der Hutschienensteuerung unterbringen und mit dem o.g. Stecker verbinden.
Anbei Bilder vom LCD-Modul und von meiner Hutschienensteuerung. Auf der Vorderseite der Steuerung befindet sich eine Sicherung, die astronomische Jahresschaltuhr von Theben, das 4-Kanal-Erweiterungsmodul davon, ein Wechselschalter um zwischen Theben und Conrad-Uhr umzuschalten (der fehlt momentan, das ist die Lücke, Bestellung ist unterwegs), daneben eine einfache Conrad-Zeitschaltuhr, die für den Notfall gedacht ist, falls die Theben ausfällt (wobei die Conrad alle 8 Kanäle gleichzeitig schalten wird, während die Theben die Kanäle getrennt schaltet), daneben ein weiterer Wechselschalter, um zwischen Zeitschaltuhr oder manuellem Betrieb umzuschalten, daneben 8 Schalter für den manuellen Betrieb und letzlich die oben erwähnte Sensoranzeige.
Auf der Rückseite befinden sich links die Steckdosen für die 8 Schaltknäle, daneben ein paar Verteiler, dann eine Dauersteckdose (für den Worstcase, dass alle Steuerungsoptionen ausgefallen sind), ein 12V Netzteil, mit dem ich den Arduino (Sensorita) betreibe, und der u.U. auch einen Lüfter versorgen könnte.
2013-03-21 - DRRAW kombinierter MRTG Graph: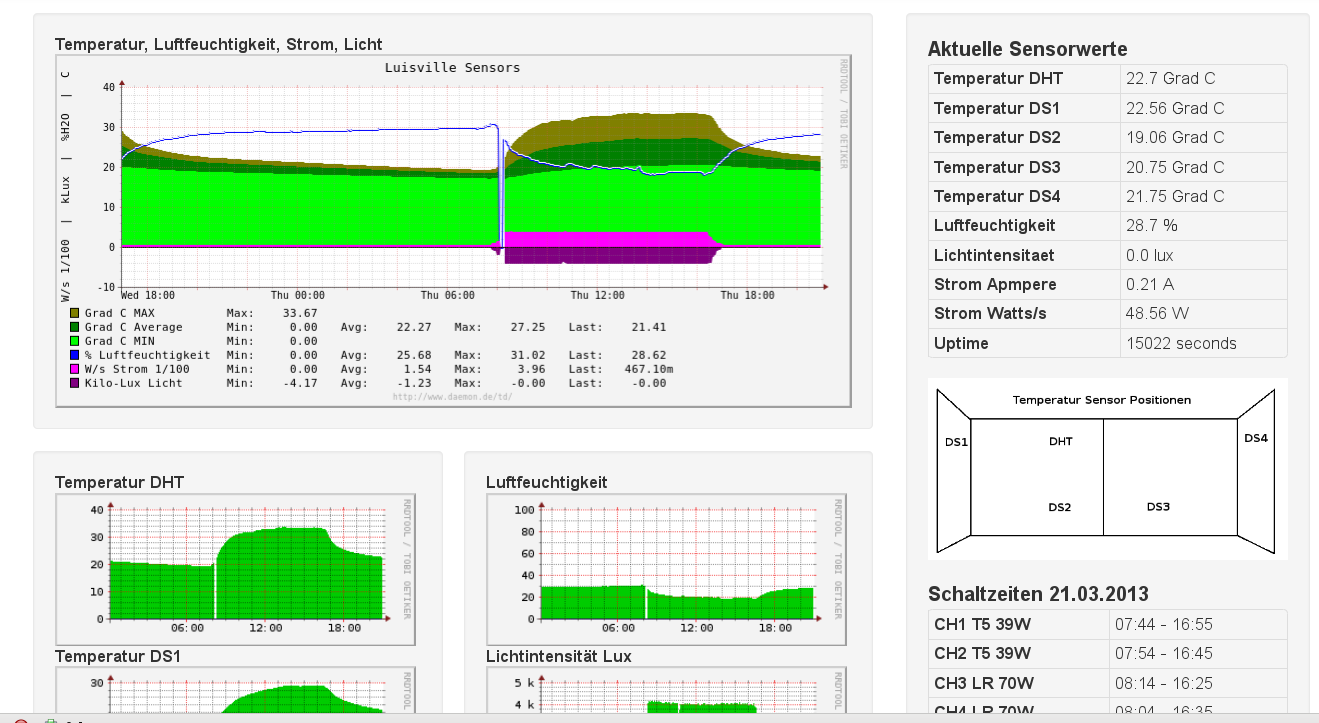
2013-03-12 - Nagios SMS bei Ausfall:
2013-03-12 - Nagios ein Ausfall: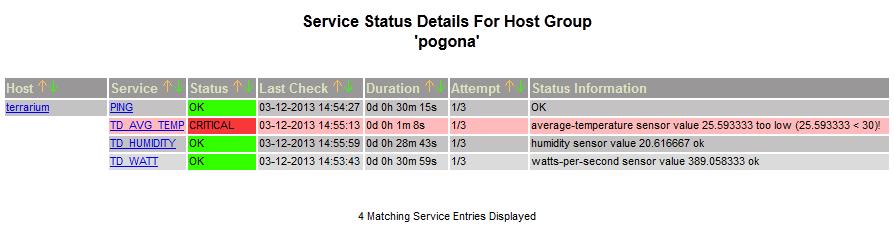
2013-03-12 - Nagios alles grün: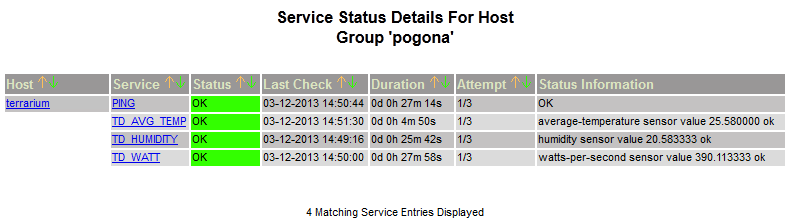
2013-03-11 - Schaltzeiten der Theben Schaltuhr: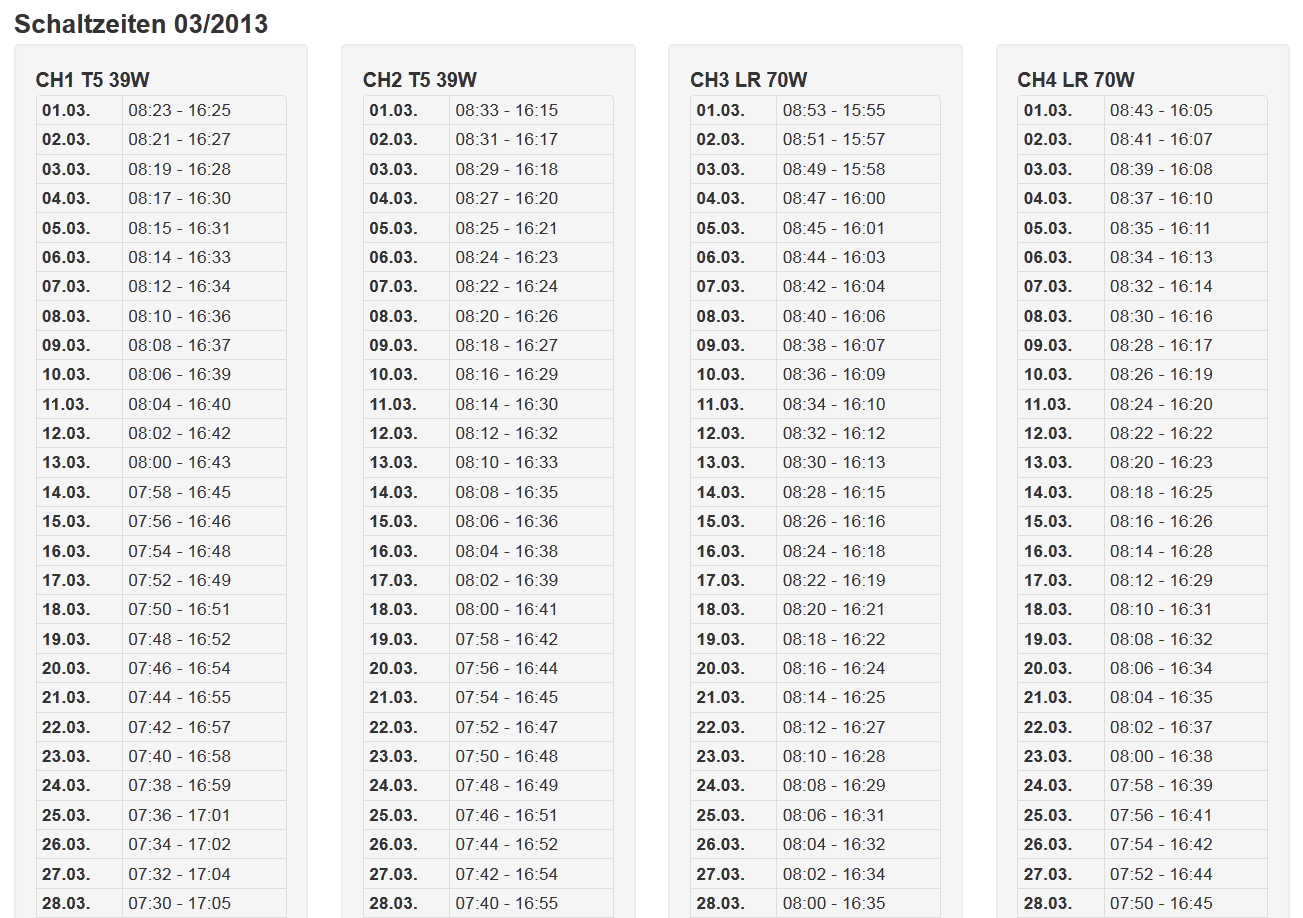
2013-03-11 - Sensorlogs in der Django DB:
2013-03-11 - MRTG und Datenanzeige: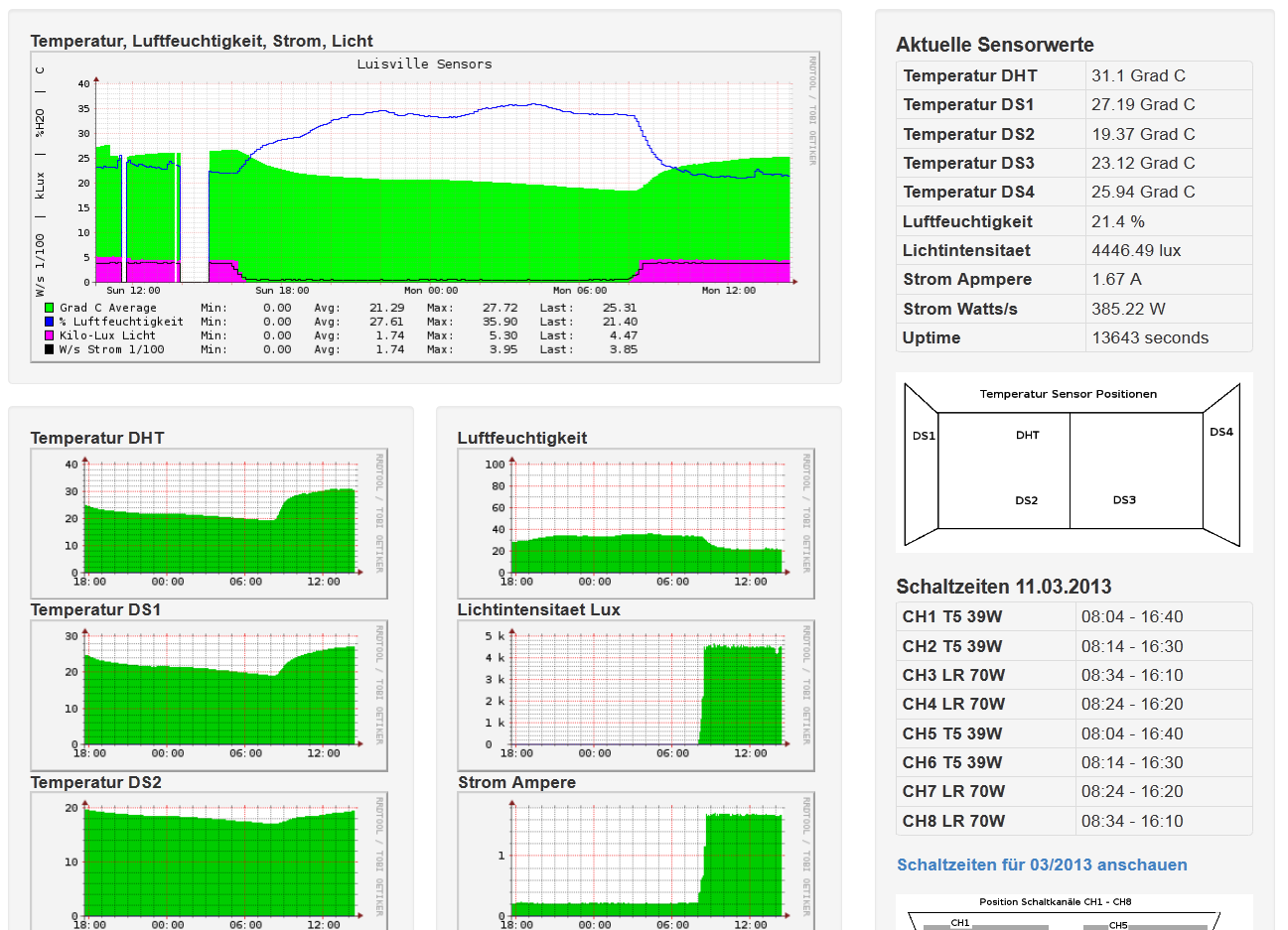
2013-03-01 - Steuerung fertiggestellt:
2013-02-10 - Alle Anzeigemenüs im Überblick:
2013-02-10 - Eingebaut ins Terrarium:
2013-01-28 - Ein Sensorkabel (mit DS1820):
2013-01-28 - Sensoren angeschlossen und in Betrieb:
2013-01-25 - Steuerung von vorn:
2013-01-25 - Steuerung von hinten:
2013-01-25 - Fertiges LCD-Sensor-Anzeige-Gehäuse:
2013-01-25 - LCD im Gehäuse eingesetzt:
2013-01-25 - LCD Platte von unten:
2013-01-25 - LCD auf Leiterplatte:
Update 2013-03-21:
Nachdem das MRTG nun eine Weile läuft, habe ich inzwischen auch einen kombinierten Graphen, in dem alle Werte gleichzeitig angezeigt werden (im Bild links oben). Dadurch kann man sehr gut die Zusammenhänge zwischen verschiedenen Dingen erkennen.Update 2013-03-12:
Jetzt, wo ich die Sensordaten erstmal in der Datenbank habe, kann ich die natürlich auch überwachen. Da ich bereits Nagios einsetze, mach ich es damit.Anbei zwei Screenshots aus meinem Nagios, einmal ohne und einmal mit (künstlichem) Alarm :) Und die SMS kann man auch bewundern :)
Update 2013-03-11:
So, das Logging hab ich jetzt auch fertiggestellt. Ich wollte dafür ursprünglich meine noch vorhandene und derzeit nicht genutzte NSLU2 benutzen. Ich hatte die deshalb geöffnet und den seriellen Port mit einem Stecker verbunden und herausgeführt. Von einem Arduino aus konnte ich dann auch tatsächlich serielle Daten (via TTL) dorthin schicken. Das Problem war nur, dass das Gerät zu unzuverlässig ist. Zum einen ist es nach diversen Reboots nicht mehr hochgekommen, da musste ich jedesmal mit Redboot rumfrickeln. Ein Scheiss. Und zum anderen läuft unter Linux der serielle Read-Buffer voll, wenn man da Daten hinschickt und die keiner abholt und das ist nur per Reboot abzustellen. Dazu kann ich nur sagen: what the bloody hell?!Also in die Tonne damit. Mir geht Linux mittlerweile sowieso nur noch auf den Zeiger. Aber sowas? Verdammtes Amateurgeraffel. Also ich verwende jetzt einen zweiten Arduino, den ich eigentlich für Testzwecke da hatte. Ich hab dem Teil einfach den Ethernetshield aus meinem Terraduinoprojekt aufgesteckt. Das hat dort sowieso nie richtig funktioniert und ich benutze es auch nicht mehr. RX und TX verbinden (witzigerweise musste ich TX nach TX und RX nach RX stecken, damit es geht, die Beschriftung ist falsch herum auf dem Teil!) und per Ethernet raus damit.
Source von Sensorita und dem Loggingmodul wie üblich bei Github.
Die Logdaten schickt das Etherlogmodul dann zu meinem Djangoserver, der es in der Datenbank ablegt. Ich schicke mehr Daten als MRTG nutzt, d.h. die tatsächliche Auflösung beträgt etwa 1 Datensatz pro Minute. Für MRTG wird aus diesen Daten ein Durchschnitt ermittelt. In den angehängten Screenshots sieht man die MRTG Graphen und auf der rechten Seite die aktuellen Sensorwerte. Im zweiten Bild sieht man die Rohdaten in der Datenbank.
Weiters habe ich herausgefunden, dass man mit der Obelisksoftware von Theben, mit der ich die Programmierung für die astronomische Jahresschaltuhr einstelle, einen CSV Export machen kann. Das hab ich natürlich sogleich ins Django eingebaut und so kann ich nun sehen, wann die einzelnen Kanäle gemäß Programmierung angehen werden. Sehr feine Sache, das.
Update 2013-03-01:
Und hier die finale Ansicht, jetzt mit Beschriftung und Legende.Update 2013-02-10:
Bei Github gibts jetzt ne neue Version, ich habe die Anzeige nochmal überarbeitet. Die Steuerung ist inzwischen auch im Terrarium eingebaut, siehe Foto. Ausserdem habe ich mal alle Anzeigemenüs fotografiert, damit man mal sieht, wie das ungefähr aussieht nachher. Der exorbitant hohe Stromverbrauch kommt von der angeschlossenen Testlampe (ein Halegenstrahler).Update 2013-02-10:
Den Sourcecode habe ich nun endlich mal bei Github eingecheckt.Update 2013-01-29:
Die Sensorita ist heute fertig geworden. War dann doch mehr Arbeit als erwartet. Aber lohnt sich. Anbei wie üblich das aktuelle Video der Endversion:
Die hohen Lux- und Watt-werte rühren daher, dass ich zum Testen einen 500 Watt Halegenstrahler angeschlossen habe. Die Hauptanzeige hab ich geändert, da werden jetzt alle Werte auf einmal dargestellt, bei der Temperatur der Durchschnitt. Mit dem grünen Knopf kommt man zu den Detailanzeigen. Dort werden dann jeweils noch Min- und Max-Werte hinzukommen.
Angeschlossene Sensoren: DHT22 (Temperatur und Luftfeuchtigkeit), Strom (Watt, Ampere, kwh), 4 x DS1820 (Temperatur) und eine Photodiode (Lux).
Ich habe auch mal den aktuellen Sourcecode hochgeladen. Ist noch nicht bei Github, kommt aber noch.
Update 2013-01-28:
Heute habe ich 5 Sensoranschlüsse verlötet (4 x DS1820 Temperatursensor und 1 x LDR) und die entsprechenden Sensorkabel hergestellt. Leider ist einer der DS1820 kaputt (das herauszufinden, hat mich über 2 Stunden Debugging gekostet!). Anbei ein Video der Sensorita in Aktion:Und ich hab noch 2 Fotos an das Posting gehängt. Auf dem Einen sieht man die komplette gerätschaft und auf dem anderen die Sensorkabel aus der Nähe (links der LDR, in der Mitte der Stecker und rechts der DS1820).
Update 2013-01-26:
Und hier noch ein Video von dem Teil in Aktion:
Man sieht, wie ich mit dem grünen Kopf durch die Untermenüs gehe. Und wenn ich eine Weile nix mache, geht es aus. Aktuell ist der Timeout natürlich noch recht kurz - zum Testen - später bleibt es eine Minute lang an.
Privacy vs. Obscurity
Heute bin ich über einen äusserst interessanten Artikel im Atlantik gestossen: Obscurity: A Better Way to Think About Your Data Than 'Privacy'. Kurz gesagt, wird dort treffend festgestellt, dass die meisten Probleme, die die Leute heutzutage mit dem Thema "Datenschutz" haben, eigentlich gar nichts damit zu tun haben, sondern mit dem Thema "Obscurity". Ich finde leider keinen passenden deutschen Begriff dafür, deshabl bleibe ich einfach beim englischen Wort.
In dem Artikel wird das am Beispiel Facebook Graph aufgezeigt. Eine Menge Leute regen sich über die Funktion auf, weil sie ihre Privatsphäre verletze. Das tut die Funktion natürlich nicht. In der Tat werden nur bereits öffentliche Informationen zusammengestellt und durchsuchbar. Geheim - im Sinne von "Keiner ausser mir kann das sehen" - war und ist davon gar nichts. Insofern kann man Facebook verstehen, wenn sie ob der Aufregung nur mit den Schultern zu zucken wissen. Immerhin haben sie an sich ja nichts verbrochen.
Das eigentliche Problem dabei ist Obscurity. Unter Obscurity versteht man das Verbergen von Informationen in der Öffentlichkeit. Das heisst, Informationen sind zwar öffentlich, aber entweder schwer zu finden oder nicht so ohne weiteres jemandem zuzuordnen. Das trifft eben zum Beispiel auf öffentliche Informationen bei Facebook zu. Likes, Kommentare von anno dazumal, ein Bild vor 2 Jahren hier, ein Posting vor einem Jahr dort - aus diesen Informationshäppchen eine verwertbare Aussage herauszuholen ist mühselig bis unmöglich. Hinter dieser Obscurity haben sich die Leute anscheinend relativ sicher gefühlt. Weil sie wussten, dass im Grunde nur Vollprofis mit Zugriff auf die Facebook-Datenbanken so etwas tun konnten.
Jetzt nicht mehr. Jetzt kann es jedermann, Graph sei Dank. Auf einmal kann man aus scheinbar zusammenhanglosen - durchaus öffentlichen - Informationen eine Aussage herausquetschen. Mit ein paar Mausklicks. Das erschreckt die Leute und sie haben Recht, es ist erschreckend. Aber mit der Privatsphäre hat das eben nichts zu tun.
Denn was ist eigentlich Privatsphäre, wenn wir über das Internet reden? Nehmen wir ein Beispiel. In einem sozialen Netzwerk taucht ein Foto von einem Arsch auf. Dabei handelt es sich um eine Information. Verletzt dieses Foto die Privatsphäre von jemandem? Nein! Und zwar, weil - wenn man nur das Bild zur Verfügung hat - man es nicht mit der Person in Verbindung bringen kann. Das Bild wurde von einem User namens "Hans" hochgeladen und nehmen wir an, es handelt sich um den Arsch von ebendiesem. Verletzt es seine Privatsphäre, wenn das Bild öffentlich ist? Nein, immer noch nicht. Denn wir wissen nur, dass es "Hans" war, wir können das Bild immer noch nicht einer echten Person zuordnen.
Tatsächlich können wir das erst, wenn wir Zugang zum Logfile des Webservers hätten, über den das Bild hochgeladen worden ist, das sähe dann zum Beispiel so aus:
172.16.1.1 - - [10/Jul/2012:18:41:02 +0000] "POST /media/user/hans/ HTTP/1.1" 345 403 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)" "http://foo.bar/user/hans/profile/"
Hier haben wir:
- eine IP Adresse
- ein Datum und Uhrzeit
- Betriebssystem
- Browser
- Referrer (wo der User vorher war)
Anhand dieser Daten kann man den Vorgang einer lebenden Person zuordnen. "Kann man" ist natürlich einzuschränken. Können kann das nur der Betreiber des Internetzugangs aus dessen Bereich die IP-Adresse kommt. Und Zugriff auf obigen Logeintrag hat nur der Betreiber des Webservers.
Wenn wir also hier über den Schutz der Privatsphäre sprechen, dann meinen wir, wie diese Daten geschützt sind:
- Wer hat Zugriff auf die Logdaten?
- Wie weit in die Vergangenheit reichen die Daten?
- Wer hat Zugriff auf die Logdaten beim Betreiber des Internetzugangs?
- Auch hier: wie weit in die Vergangenheit reichen die Daten?
Diese Fakten sind der Datenschutz. Und zwar NUR diese. Alles andere betrifft im Grossen und Ganzen das Thema Obscurity. Wenn also jemand sagt, Facebook würde die Privatsphäre der Nutzer verletzen, dann sollte er damit meinen, dass die Logdaten, die bei einem POST- oder GET-Request auf Facebooks Webservern erscheinen, zu lange vorgehalten werden, oder dass Leute auf die Daten Zugriff haben, die das nicht sollten (zum Beispiel externe Entwickler oder Ermittlungsbehörden ohne Gerichtsbeschluss).
Man wird jetzt einwenden können, dass das zu kurz gedachtt ist, denn immerhin verwenden die Leute bei Facebook ja ihren echten Namen, über diesen seien Informationen einer Person zuzuordnen. Das ist theoretisch richtig. Bei Lichte betrachtet jedoch nicht. Zwar schreiben die AGB von Facebook die Verwendung des echten Namens vor, aber AGB haben keinen Gesetzesrang. Mithin zwingt niemand die Menschen, dort ihren echten Namen zu verwenden. Und tatsächlich gibt es genug Leute, die das auch nicht tun. Hinzu kommt der vielleicht nicht unbedeutende Aspekt, dass man aus diesem Grund auch nie ganz genau wissen kann, ob der Facebooknutzer mit dem Namen "Hans Wurst" wirklich DER Hans Wurst, Foostrasse 1, 11111 Bardorf, ist. Es könnte auch dessen Frau sein, oder sein Sohn, ein Nachbar, oder sonstwer, der womöglich zufällig auch so heisst. 100%ig wissen kann man es nicht. Das kann man NUR, wenn man Zugriff auf die PRIVATEN Daten des Nutzers hat, also das Logfile des Webservers bei Facebook.
Davon abgesehen finde ich es immer wieder faszinierend, dass sich Leute über das Thema Datenschutz erregen, die bei Facebook ihren echten Namen verwenden. Völlig freiwillig. Aber nur weil sie das tun, heisst das nicht, dass es dadurch automatisch Facebooks Schuld ist, wenn private Details über deren Leben ans Tageslicht geraten. Es handelt sich um eine persönliche Entscheidung, die man so oder so fällen kann. Dies impliziert somit, dass die Verantwortung bei demjenigen liegt, der die Entscheidung getroffen hat.
Teil dieser Entscheidung, für die es durchaus akzeptable Gründe geben kann, ist die Frage, wieviele echte Details über sich selbst eine Person mit diesem Datum - dem Namen - verknüpft. Die Anhänger der sogenannten Spackeria beantworten diese Frage sehr einfach mit: alles, womit Du leben könntest, wäre es weltweit für jeden sichtbar. Gibt es also ein Detail, mit dem ich ein Problem hätte, wüsste es jeder, dann sollte ich dieses Detail NICHT posten und somit mit meinem echten Namen verknüpfen. Sollte es aber notwendig sein, sich mit jemandem darüber auszutauschen, dann tut man das, indem man Obscurity herstellt: man verwende ein Pseudonym und stelle es in einem anderen Netzwerk/Forum ein und diskutiere es dort.
Wenn man sich an diese kleine, einfache Regel hält, wird es niemandem überhaupt möglich sein, die Privatsphäre zu verletzen (von Kriminellen, Gesetze misachtenden Konzernen und Behörden und verfassungsmissachtenden Gesetzgebern einmal abgesehen). Es wird jedoch möglich sein, den Schleier der Obscurity zu senken. Vielleicht jedenfalls. Irgendwann einmal. So wie es heutzutage mit Facebook Graph passiert ist, mag es morgen ein neues Tool geben, dass in der Lage ist, Dinge zu verknüpfen.
Man muss von einer Wahrscheinlichkeit von 1 ausgehen, dass das passieren wird. Und zwar immer, mit allem, was man von sich preisgibt. Es muss immer klar sein: irgendwann wird das jemand mit anderen Informationen verknüpfen können und womöglich wird es jemandem möglich sein, diese miteinander verknüpften Informationen - die neue Aussage - meiner Person zuzuordnen, weil ein Datum aus diesen Informationen bereits mit meiner Person verknüpft ist.
Das einzige Problem ist, dass sowohl millitante Datenschützer, als auch Spackeria-Anhänger, anscheinend nicht in der Lage sind, das Problem und die naheliegende Lösung so zu formulieren, dass man daraus eine Handlungsweise ableiten kann. Ich hab das hier mal probiert. Hinzu kommt, dass das präzise die Methode ist, mit der ich mich im Internet bewege. Ich bin seit fast 20 Jahren online und meine Spuren sind dünn. Äusserst dünn. Aber das heisst nicht, dass ich nie etwas poste oder mit Leuten kommuniziere. Tue ich schon, nur weiss keiner, dass ich es bin. Es sei denn, ich will es so.
↷ 22.01.2013 🠶 #gesellschaft ⤒
Temperatursensor DS1820 mit Arduino Micro und 128x32 OLED Display - Test
Für mein nächstes Projekt habe ich schonmal die ersten Komponenten verwurstet und getestet. Der DS1820 mit der Dallas-Library und OneWire funktioniert 1a, wobei bei mir der parasitäre Modus nicht ging, ich muss also Pin 3 auf VCC hängen, dann geht es. Als Display hab ich ein 128x32 Oled-Display. Ich war recht erschrocken, wie klein das ist, aber man kann es erstaunlich gut ablesen. Ausserdem bietet die Library verschiedene Schriftgrössen.
Ich habe das Breedboard eine Weile aus dem Fenster gehalten und nachher wieder reingenommen:
Update 2013-01-16:
Jetzt habe ich auch noch einen LDR (Photowiderstand) angeschlossen, der die Lichtintensität in Lux misst. Da unkalibriert, natürlich ein wenig ungenau, aber immerhin:
Hier bewege ich das Breedboard langsam immer näher an die Lampe und der Luxwert steigt auch. Wenn ich den Finger drüberhalte, sinkt er erwartungsgemäß. Ich hab den Wert ein bischen "kalibriert", indem ich verschiedene Referenzwiderstände ausprobiert habe und mit einer Luxtabelle verglichen habe. In Produktion müsste ich das natürlich mit einem Luxmeter und einem Potentiometer kalibrieren oder gleich einen digitalen Sensor benutzen.
Update 2013-01-15:
Da ich es in der Grabbelkiste gefunden hatte, hab ich heute auch noch das 16x2 LCD angeschlossen und getestet. Geht auch:
Ja, was besseres ist mir nicht eingefallen und die Beifahrerin wird es zu schätzen wissen :)
Ausserdem habe ich an dem Teil auch mal den DS1820 gehängt und zusätzlich Min- und Max-Werte gespeichert und angezeigt, das sieht dann so aus:

Coole Sache, das!
Der Nektar der Götter
Über Arts and Letters Daily habe ich heute folgenden Artikel gefunden: The art of coffee. Man muss es selber lesen. Sehr erhellend. Zusammengefasst geht es darum, was die fortschreitende Automatisierung mit uns macht. Das Beispiel des Autors ist Espresso, welcher in Restaurants zunehmend nur noch mit Maschinen hergestellt wird. Er stellt fest, dass dieser maschinenerzeugte Espresso in aller Regel besser ist als Handgemachter. Nur wirkliche echte Meister können die Maschine übertreffen, aber die sind selten (und werden noch seltener DURCH die Maschinen).
Es gibt aber noch eine weitere Komponente bei unserem Konsum. Wir schauen nicht nur, ob ein Produkt gut ist. Wir wissen auch um seinen Herstellungsprozess. Der Kontext ist entscheidend. Es ist einfach etwas anderes, wenn man WEISS, dass sich da ein echter Mensch manuell richtig Arbeit gemacht hat mit all seinem Können, seinen Erfahrungen und seiner Liebe zum Beruf. Selbst wenn das Resultat streng nach objektiven Messwerten betrachtet schlechter als die maschinelle Konkurrenz ist. Deshalb kommen Bioprodukte gut an. Oder Fairtrade Kaffee. Weil wir wissen, dass sich hinter diesen Produkten keine gesichtslosen Konzernmonster mit vollautomatischen Fabriken verbergen.
Ein weiteres Problem, das ich dabei sehe, das der Autor nur kurz anschneidet, ist der Verlust von Wissen. Eines Tages wird es niemanden mehr geben, der weiss, wie man eine bestimmte Sache von Hand herstellt. Es wird sicher dokumentiert sein, bei Wikipedia oder sonstwo. Aber das wird niemandem helfen. Wenn ich mir überlege, wie das abläuft wenn mir mein Schwiegervater irgendwelche handwerklichen Arbeiten beibringt: ich weiss im Grunde wie man eine Türzarge einsetzt, rein theoretisch. Aber da gibt es tausend Kniffe, die man beachten muss und mit denen man sich behelfen kann. Die stehen nirgends. Wenn er geht, geht dieses Wissen mit ihm. Ich habe nur einen klitzekleinen Bruchteil davon abgreifen können.
Und so wird das mit immer mehr Spezialwissen passieren. Sobald es jemandem gelungen ist, einen manuellen Herstellungsprozess mathematisch auszudrücken und maschinell zu implementieren, werden die Leute aufhören sich darum zu kümmern. Auch in meiner Branche, der IT, ist das nicht anders. Mein Spezialgebiet Internetbackbone/BGP wird zunehmend dünner. Immer weniger Provider teilen sich den Markt und immer mehr Aufgaben kann man automatisieren, weshalb immer weniger Leute notwendig sind, die sich um das Thema kümmern müssen. Tatsächlich bin ich bei mir im Unternehmen der Einzige, der das tut. Es gib einen Kollegen, der Backup macht, aber der kümmert sich seit Jahren primär um andere Dinge. Und wir haben keine Lehrlinge, denen ich das beibringen könnte. Und selbst wenn wir welche hätten: wozu sollte ich? Wie gross ist die Wahrscheinlichkeit, dass ein Fachinformatiklehrling später mal einen Job bei einem ISP bekommt, wo er sich mit BGP befassen muss? Sicher im Promillebereich. Und meinen Nachwuchs interessiert es auch nicht.
Und auf diese Weise wird unsere Zivilisation immer abhängiger von sich selbst. Alles steht und fällt mit der Verfügbarkeit unserer Maschinen. Nähme man uns die weg, würden wir umgehend in der Steinzeit landen. Und dieses Risiko wird in Zukunft keineswegs kleiner werden. Schon jetzt werden viele Maschinen, die Konsumentenprodukte herstellen, von Maschinen gebaut. Das wird so weitergehen. Maschinen bauen Maschinen, die Maschinen bauen, die Maschinen bauen, die Dosenöffner herstellen. Und überhaupt kein einziger Mensch wird auch nur den Hauch eines Schimmers mehr haben, wie das alles insgesamt funktioniert. Und niemand wird mehr in der Lage sein, dieses Gesamtsystem neu aufzubauen, sollte sich das als notwendig erweisen. Sozusagen ein Henne-Ei-Problem, bei dem das Ei abhanden gekommen ist.
Tja. Ich schliesse mit einem Zitat aus einem Kommentar zum oben verlinkten Artikel, den ich hervorragend pointiert fand:
When the table is surrounded by friends and full of good food and dappled by the sun reaching through the wisteria, a two pound bottle of red plonk becomes the very nectar of the gods.