Posts on tag: source
Table of contents
New shell gimmicks
So, I decided to streamline my shell config the other day. The very first I did, was to write an awk replacement in perl. Sounds a little senceless, but sometimes I need some more power inside an awk command and sometimes I just want to save typing. This is how it looks like, when used:
# awk version:
ps | grep sleep | grep -v grep | awk '{print $1}' | xargs kill
# pwk version:
ps | grep sleep | grep -v grep | pwk 1 | xargs kill
This is the simple variant, which just saves typing, pretty handy. The other variant is more perlish and at first looks like the original awk syntax. Hover, you can add almost any kind of perl code to it:
ps | pwk 'if($5 =~ /^python$/) { $t=`fetch -o - "http://$8/"`; if($t =~ /<title>(.+?)<\/title/) { print "$8: $1"} }'
Here's the shell function, just put it into your .bashrc:
pwk () {
if test -z "$*"; then
echo "Perl awk. Usage:"
echo "Perlish: pawk [-F/regex/] [-Mmodule] <perl code>"
echo " Simple: pawk <1,2,n | 1..n>"
echo "Perlish helpers:"
echo " p() - print field[s], eg: p(\$1,\$4,\$7)"
echo " d() - dump variables, without param, dump all"
echo " e() - exec code on all fields, eg: e('s/foo/bar/')"
echo
echo "Default loaded modules: Data::Dumper, IO::All"
echo "Enable \$PWKDEBUG for debugging"
echo "Simple mode has no helpers or anything else"
else
# determin pwk mode
if echo "$*" | egrep '^[0-9,\.]*$' > /dev/null 2>&1; then
# simple mode
code=`echo "$*" | perl -pe 's/([0-9]+?)/\$x=\$1-1;\$x/ge'`
perl -lane "print join(' ', @F[$code]);"
else
# perl mode
# prepare some handy subs
uselib="use lib qw(.);"
subprint="sub p{print \"@_\";};"
subsed='sub e{$r=shift; foreach (@F) { eval $r; }};'
subdump='sub d {$x=shift||{_=>$_,S=>\@F}; print Dumper($x);};'
begin="; BEGIN { $uselib $stdsplit $subprint $subdump $subsed}; "
# extract the code and eventual perl parameters, if any
code=""
args=""
last=""
for arg in "$@"; do
args="$args $last"
last="$arg"
done
code=$last
# fix perl -F /reg/ bug, complains about file /reg/ not found,
# so remove the space after -F
args=`echo "$args" | sed -e 's/-F /-F/' -e 's/-M /-M/'`
# convert $1..n to $F[0..n]
code=`echo "$code" | perl -pe 's/\\\$([0-9]+?)/\$x=\$1-1;"\\\$F[\$x]"/ge'`
# rumble
defaultmodules="-MData::Dumper"
if perl -MIO::All -e0 > /dev/null 2>&1; then
defaultmodules="$defaultmodules -MIO::All"
fi
if test -n "$PWKDEBUG"; then
set -x
fi
perl $defaultmodules $args -lane "$code$begin"
if test -n "$PWKDEBUG"; then
set +x
fi
fi
fi
}
Another new shell function is extr, which unpacks any kind of archive. In contrast to its sisters out there (there are a couple of generic unpack shell funcs to be found on the net), it takes much more care about what it does. Error checking, you know. And it looks inside the archive to check if it extracts into its own directory, which is not always the case and very annoying. In such instances it generates a directoryname from the archivename and extracts it to there. Usage is simple: extr archivefile. Here's the function:
extr () {
act() {
echo "$@"
"$@"
}
n2dir() {
tarball="$1"
suffix="$2"
dir=`echo "$tarball" | perl -pne "s/.$suffix//i"`
dir=`basename "$dir"`
echo "$dir"
}
tarball="$1"
if test -n "$tarball"; then
if test -e "$tarball"; then
if echo "$tarball" | grep -Ei '(.tar|.jar|.tgz|.tar.gz|.tar.Z|.tar.bz2|tbz)$' > /dev/null 2>&1; then
# tarball
if echo "$tarball" | grep -E '.(tar|jar)$' > /dev/null 2>&1; then
# plain old tarball
extr=""
elif echo "$tarball" | grep -E '(bz2|tbz)$' > /dev/null 2>&1; then
extr="j"
elif echo "$tarball" | grep -E 'Z$' > /dev/null 2>&1; then
extr="Z"
else
extr="z"
fi
if ! tar ${extr}tf "$tarball" | cut -d/ -f1 | sort -u | wc -l
| egrep ' 1$' > /dev/null 2>&1; then
# does not extract into own directory
dir=`n2dir "$tarball" "(tar.gz|tgz|tar.bz2|tbz|tar|jar|tar.z)"`
mkdir -p $dir
extr="-C $dir -${extr}"
fi
act tar ${extr}vxf $tarball
elif echo $tarball | grep -Ei '.zip$' > /dev/null 2>&1; then
# zip file
if unzip -l "$tarball" | grep [0-9] | awk '{print $4}' | cut -d/ -f1 | sort -u \
| wc -l | egrep ' 1$' /dev/null 2>&1; then
# does not extract into own directory
dir=`n2dir "$tarball" zip`
act mkdir -p $dir
opt="-d $dir"
fi
act unzip ${opt} $tarball
elif echo "$tarball" | grep -Ei '.rar$' > /dev/null 2>&1; then
if ! unrar vt "$tarball" | tail -5 | grep '.D...' > /dev/null 2>&1; then
# does not extract into own directory
dir=`n2dir "$tarball" rar`
act mkdir -p "$dir"
(cd "$dir"; act unrar x -e $tarball)
else
act unrar x $tarball
fi
elif echo "$tarball" | grep -Ei '.gz$' > /dev/null 2>&1; then
# pure gzip file
act gunzip "$tarball"
else
:
fi
else
echo "$tarball does not exist!"
fi
else
echo "Usage: untar <tarball>"
fi
}
And finally an updated version of my h function, which can be used for dns resolving. Usage is pretty simple:
% h theoatmeal.com ; dig +nocmd +noall +answer theoatmeal.com theoatmeal.com. 346 IN A 208.70.160.53% h 208.70.160.53 ; dig -x 208.70.160.53 +short oatvip.gpdatacenter.com.
% h theoatmeal.com mx ; dig +nocmd +noall +answer theoatmeal.com mx theoatmeal.com. 1800 IN MX 5 eforwardct2.name-services.com. theoatmeal.com. 1800 IN MX 5 eforwardct3.name-services.com. theoatmeal.com. 1800 IN MX 5 eforwardct.name-services.com.
It uses dig to do the work, or host if dig cannot be found. The source:
h () {
if type dig > /dev/null 2>&1; then
args="$*"
opt="+nocmd +noall +answer"
rev=""
if echo "$args" | egrep '^[0-9\.:]*$' > /dev/null 2>&1; then
# ip address
cmd="dig -x $* +short"
else
# hostname
cmd="dig +nocmd +noall +answer $*"
fi
echo "; $cmd"
$cmd
else
# no dig installed, use host instead
host="$1"
type="a"
debug=""
cmd="host $debug"
if test -z "$host"; then
echo "Usage: h <host> [<querytype>]"
return
else
if test -n "$2"; then
type=$2
fi
if test -n "$debug"; then
set -x
fi
case $type in
ls)
$cmd -l $host
;;
any)
cmd=`echo $cmd | sed 's/\-d//'`
$cmd -d -t any $host | grep -v ^\; | grep -v "^rcode ="
;;
mx|a|ns|soa|cname|ptr)
$cmd -t $type $host
;;
*)
echo "*** unsupported query type: $type!"
echo "*** allowed: mx, a, ns, any, *, soa, cname, ptr"
continue
;;
esac
if test -n "$debug"; then
set +x
fi
fi
fi
}
subst update (1.1.3)
So, after a couple of idle years I made an update to my subst script. Although I use it everyday there were still some glitches here and there. For one, I just could not rename files with spaces in them. Very annoying. Also it was unflexible in that I could not use additional perlmodules when using /e. STDIN was not supported among other minor stuff.
So, the new version fixes all this, see the link above. Download, rename it (remove the .txt extension) and put it into your bin directory. Usage:
Usage: subst [-M <perl module>] [-t] -r 's/old/new/<flags>' [ -r '...', ...] [<file> ... | /regex/]
subst [-M <perl module>] [-t] -m 's/old/new/<flags>' [ -m '...', ...] [<file|dir> ... | /regex/]
Options:
-r replace contents of file(s)
-m rename file(s)
-M load additional perl module to enhance /e functionality.
-t test mode, do not overwrite file(s)
Samples:
-
replace “tom” with “mac” in all *.txt files: subst -r ’s/tom/mac/g’ *.txt
-
rename all jpg files containing whitespaces: subst -m ’s/ /_/g’ ‘/.jpg/’
-
decode base64 encoded contents subst -M MIME::Base64 -r ’s/([a-zA-Z0-9]*)$/decode_base64($1)/gem’ somefile
-
turn every uri into a link subst -M “Regexp::Common qw /URI/” -r ’s#($RE{URI}{HTTP})#<a href="$a">link</a>#g’ somefile
If <file> is -, STDIN will be used as input file, results will be printed to STDOUT. -t does not apply for STDIN input.
Substitution regex must be perlish. See ‘perldoc perlre’ for details.
Version: 1.1.3. Copyright (c) 2002-2014 - T.v.Dein <tom AT linden DOT at>
So, in order to remove spaces of filenames, I can now just issue:
subst -m 's/ /_/g' '/\.mp3$/'
As you can see, instead of giving a shell wildcard as last argument, I provide a regex, which will be resolved by the script itself from the current directory. Bam!
Der Vorteil von Fuzzytests
Ich habe am Wochenende angefangen, die PCP Library (libpcp) threadsafe zu machen. Zu diesem Zweck habe ich ein Context-Objekt eingeführt, in dem vormals globale Variablen abgelegt werden (Fehler und Schlüssellisten). Jetzt habe ich nach der Änderung (die tiefgreifend ist) das erste Mal die Unittests durchlaufen lassen und einer der Tests ist fehlgeschlagen:
executing prepare command: while :; do cp testfuzzP.orig testfuzzP.pub; ./mangle testfuzzP.pub;
if ! diff testfuzzP.* > /dev/null 2>&1; then break; fi; done
echo no | ../src/pcp1 -V vf -K -I testfuzzP.pub -x a
ok 81 - check-fuzz-binary-pubkey-loop-0
Abnormal program termination
Core was generated by `pcp1’.
Program terminated with signal 6, Aborted.
#0 0x0000000800db9d6c in kill () from /lib/libc.so.7
#0 0x0000000800db9d6c in kill () from /lib/libc.so.7
#1 0x0000000800db899b in abort () from /lib/libc.so.7
#2 0x0000000000407f8c in final (fmt=Variable “fmt” is not available.
) at context.c:102
#3 0x00000000004100f2 in buffer_get_chunk (b=0x80149b100, buf=0x80149c080, len=3932164) at buffer.c:132
#4 0x00000000004122d3 in _check_sigsubs (blob=0x80149b100, p=0x801407c00, subheader=0x8014a7060) at mgmt.c:103
#5 0x00000000004126bf in pcp_import_pub_rfc (ptx=0x801417040, blob=0x80149b100) at mgmt.c:265
#6 0x0000000000403e34 in pcp_import (vault=0x80141a060, in=0x8010099d0, passwd=0x801419104 “a”) at keymgmt.c:577
#7 0x0000000000402df2 in main (argc=0, argv=0x7fffffffd170) at pcp.c:440
Last failed check: check-fuzz
1..81
To run a single test only, type: ‘make test CHECK=testname’
Ich hab das Problem jetzt noch nicht näher untersucht. Spannend ist aber, dass es der Fuzzytest war, der hier fehlgeschlagen ist (hat wahrscheinlich nichts mit der Contextänderung zu tun). Bei einem Fuzzytest wird randomisiertes Input erzeugt und das zu testende Programm damit gefüttert. Idealerweise sollte es mit solchem Zeug klarkommen. In diesem Fall ist pcp1 aber gestorben.
Noch wesentlich interessanter ist warum. Und zwar habe ich - gleichzeitig - in der Bufferklasse eine Änderung gemacht, bei der potentielle Bufferoverflows, die dort abgefangen werden, nicht via fatal() über den normalen Programmfluß reportet werden, sondern ich habe an der Stelle ein abort() eingebaut. Und an der Stelle ist dieser Fuzzytest hier gescheitert. Man kann das besser erkennen, wenn man den Test manuell ausführt:
echo no | ../src/pcp1 -V vf -K -I testfuzzP.pub -x a ABORT: [buffer importblob] attempt to read 3932164 bytes data from buffer with 204 bytes left at offset 113 Abort trap: 6 (Speicherabzug geschrieben)
Die Fehlermeldung wird in libpcp/buffer.c erzeugt. Woher das kommt, ist mir im Moment zwar noch nicht ganz klar. Es sieht verdächtig nach Integer Overflow aus: in der zu importierenden Schlüsseldatei gibt es normalerweise Felder für Email, Name und dergleichen (Notations, siehe RFC 4880). In der Notation ist die Länge des Strings angegeben und durch das kaputte Inputfile (das wird mit mangle.c, oben verlinkt, erzeugt) steht an der Stelle wahrscheinlich eine ziemlich grosse Zahl. Und offensichtlich prüft meine Importroutine nicht, ob diese Zahlenangabe Sinn macht. Aber das spielt an der Stelle erstmal keine Rolle. Der Fehler zeigt jedenfalls eindrucksvoll, wie wertvoll und nützlich solche Fuzzytests sind. Zum Glück hab ich die eingebaut! Wer weiss, ob ich den Fehler andernfalls je gefunden hätte. Uff.
Fies, aber schön :)
Der Vollständigkeit halber: in diesem Commit kann man ab Zeile 73 die Änderungen sehen, mit denen ich das Problem behoben habe.
Besser spät als nie :)
Hach, das ist ja mal eine kuriose Nummer, dieser Bug. Aber von vorn: gestern habe ich (in der Arbeit) wegen einem Perlproblem herumgegoogelt und eines der Suchergebnisse war ein Posting bei Perlmonks wegen einem Config::General Problem. In dem Posting hatte jemand Schwierigkeiten, ein Makefile mit meinem Modul zu parsen, in dem sich "line continuations" befanden. Die entsprechende Stelle in dem Makefile sah so aus:
THIS_BREAKS = \MULTILINE =
Foo
Bar
Baz
Config::General hat dann nach dem Parsen das hier ausgespuckt:
THIS_BREAKS => "MULTILINE\t= Foo\tBar\tBaz",
was der Fragesteller als Fehler betrachtete. Peter Jaquiery hat dann für mein Modul einen Bug eröffnet: 39814. In der Fehlerbeschreibung hat er aber von dem oben beschriebenen Problem nichts erwähnt, sondern nur gemeint, ein chop() Aufruf sei falsch. Das war aber Absicht, also hab ich den Bug geschlossen (rejected).
Das war vor 6 Jahren!
Nun bin ich also gestern über dieses Perlmonks Posting gestolpert, bei dem ganz unten zu jenem Bug verlinkt war. Natürlich erschien das Problem nun in einem völlig anderen Licht. Der Bug war sogar unerwarteterweise recht einfach zu beheben, was ich soeben gemacht habe.
Odd ist wirklich die passende Beschreibung für den Vorgang. 6 Jahre! Meine Güte :)
Code Review lulzlabs Radio AirChat
Yesterday someone announced AirChat on the cypherpunks mailinglist. He didn't provide any comment as to what it is or why he posted it. However I took a look anyway. I found some really odd piece of software and decided to publish a review about it. Please note, that I only looked at the code. I didn't install it and I didn't run it (I've got no radio device anyway). So, this review is not about usage, user interface or something, it's only about the code and the security implications from what I found there.
What is AirChat radio?
AirChat is a perl script and according to their README, it can be used to communicate encrypted via radio signals. No internet or mobile required, so they say.
Summary
The code in the script is a mess. One monolithic script which contains keys, configuration, html code, css code, almost no comments. It ignores all perl standards of perl software distribution (build, packaging, unit tests, documentation). The script has obviously been written by different authors (or the main author copy/pasted code from somewhere else) in different styles and paradigmas. It looks much like the old perl scripts of the late 1990s. AirChat is one of the worst security softwares I've ever seen. I would not encourage anyone using it.
Source Organization
Essentially, there's none. The software consists of one file (airchat.pl), which contains everything, like modules, html code, configuration, daemon code, ui code, hardware interfacing code and so forth.
AirChat completely ignores all perl standards about how to distribute perl software. There's no MakeMaker Makefile.PL, there are no unit tests and practically no documentation. The README file consists in large parts of prosa text, where the author(s) tell about their motives to create the software. Though it contains information how to install the software, there is no single hint about usage beside telling the user to connect with the browser to localhost to some port.
Coding Style
The script uses both whitespace and tabs for indentation. As a result the overall code looks messy, sometimes it's difficult to read it. Here's an example:
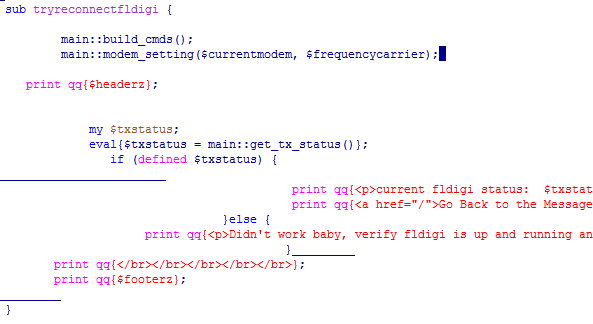
(the long underscored lines come from emacs syntax highlighting, these are whitespaces)
The script is also styled in different ways. I'd assume it have been written by different authors or the author used code from somewhere else.
The AirChat script uses some very - ahem - weird variable names. Here are some examples:
my $cock;
$settings->{'settings'}{'penis'}{'penis'} = 'also cocks' ;
my $penispenis = " ";
%dahfuckingkeys = %{$getem};
my @sortedshit = split("##END##",$pack);
$dahpassiez = Crypt::CBC->random_bytes('4096');
Obviously the author is fixated on male sexual organs. Another example of this are the modem_* functions. For example the function modem_setting() returns the literal string "penis" as do several others for no reason. Function names follow this pattern as well. Some examples: sendthefuckout(), resenditpl0x() or gogogodispatch().
Beside variables there are also gems like this:
if ($mustEncrypt eq "yeahbabygetthisoneintoyourassFCCandNSA") {
Comments in the code are rare. When there is a comment, it comments the obvious in most cases or is just senseless. An example:
## youz taking drugz again
Because of missing comments and no code documentation in general it is difficult to follow the program flow in order to figure out, what the script does.
Perl
The perl code in airchat.pl is inefficient, hard to read, inconsistent and old styled. One good thing can be noted though: the author has enabled strict and warnings, and uses my (or our) keywords to avoid undefined behavior. In most cases he also checks for validity. However there's not much error handling in the script. That is, an action will be done if a variable X is set, but there's no code for the case when it isn't. That's not always the case, but can be found all over the script. Here's one example of poor error checking (and reporting):
eval{$ctx = $cipher->encrypt($txpack)};
eval{$useThisk = $cipher->encrypt($useThisk)};
if ($@) {
print "error encrypting";
} else {
[..]
Only the eval() error of the second encrypt call is being checked. If the first one fails gets ignored. It's also not clear why he's using eval() at all.
airchat.pl contains lots of global variables and some of them are scattered throughout the script. I counted 76 global variables, however, some of them are part of the module AirChatServer (contained within the script).
It is obvious that the author is inexperienced when it comes to perl data structures. Here's a snippet of the function load_settings():
$proxyhost = $settings->{'settings'}{'Tor and Proxy'}{'proxyhost'} if defined $settings->{'settings'}{'Tor and Proxy'}{'proxyhost'} ;
$proxyport = $settings->{'settings'}{'Tor and Proxy'}{'proxyport'} if defined $settings->{'settings'}{'Tor and Proxy'}{'proxyport'} ;
$proxyuser = $settings->{'settings'}{'Tor and Proxy'}{'proxyuser'} if defined $settings->{'settings'}{'Tor and Proxy'}{'proxyuser'} ;
$proxypass = $settings->{'settings'}{'Tor and Proxy'}{'proxypass'} if defined $settings->{'settings'}{'Tor and Proxy'}{'proxypass'} ;
That's a lot of repeated typing. In general, the author uses a global hash %settings to store configuration which is to be saved to a configuration file, but doesn't use that hash. Instead he assigns every single value in that hash to a single global variable. He does the reverse when saving it to the configuration file.
Despite the notion of Windows in the documentation, the script isn't portable, since it's using hardocded unix filesystem separators:
open(F, '<', "$foolder/.AirChatsettings") or die "cannot open file settings";
Instead he should use the File::Spec perl module which does stuff like this in a portable way. There's also no check if the configuration directory, which is the script location, is writable (save_settings()). The same applies for saved messages (whatever kind of message it tries to save) and saved public keys.
The author is not very familiar with regular expressions as well. Let's take a look at this example:
if ($kxcode[1] =~ m/:CTALK2:[0-9a-f][0-9a-f][0-9a-f][0-9a-f][0-9a-f][0-9a-f]/ ) {
He's essentially checking for a hex value, but he doesn't know of perl regex quantifiers, such as: [0-9a-f]{6}. Variations of the above regex can be found throughout the whole script. There's another issue which the above line shows us: hardcoded values. And there are lots of them. Things like "OHAITHERE" or "HOTELINDIA", sizes, protocol codes (I'll come to that later) and stuff like this. Here's an example of a hardcoded size value:
my $kidx = substr($kidx,0,6);
Here the author extracts the first 6 chars of a hexstring and uses it as a key id (see below). Key id extraction code like this is scattered overall in the script, everwhere using the hardcoded 6.
Speaking of hardcoded stuff. airchat.pl contains a webserver as well (it's being used to interface to the user, I think) and a couple of builtin CGI functions. Those functions use print() statements to put HTML out. Lots of them. The author seems to be not very familiar with HTML as well, eg:
print qq { <a href="/addKey" ><code>add a new key</code></a>};
There's even an embedded font file (base64 encoded). Maintaining that stuff must be very hard. Since the HTML and style is hardcoded in the script it can't be customized (if a user wanted to do that) or translated.
There are a lot more issues. I just covered a couple of them.
Security
The airchat.pl script is completely unsecure despite the repeated "fuck the NSA" references here and there in the script and the README. It's (trying to) use RSA and AES and Camilla Ciphers along with SHA2 for hashing. When looking at the code, it looks like it's using RSA public key crypto to exchange keys with peers (via radio?). However, it's not using it at all. The reason is, that every encryption key for symmetric encryption, which is being used to encrypt messages, uses hardcoded keys. Here are the keys I found:
- 'b0ssjP3n1s+d2y0l0+IATTsuxiOB1vz7 - being used in asym_encrypt(), asym_decrypt(), sendinghits(), gettingdecodedmsg()
- 'x3UstrV@Hl;Mm#G9#_q,suckXZ$O^;55jlT*' - used as passphrase with Crypt::CBC.
- there are twitter API keys in the script!
Basically the script encrypts a randomly generated ephemeral key using RSA but then ignores it and uses the above hardcoded key for symmetric encryption. SeeUpdate below!
Random bytes are always generated this way:
$dahpassiez = Crypt::CBC->random_bytes('4096');
He should have been using Crypt::Random or Bytes::Random::Secure instead. From the Crypt::CBC docs:
$data = random_bytes($numbytes)
Return $numbytes worth of random data. On systems that support the "/dev/urandom" device file, this data will be read from the device. Otherwise, it will be generated by repeated calls to the Perl rand() function.
Beside those two major issues it generates key id's in a bad fashion:
my $rsa = Crypt::OpenSSL::RSA->generate_key(2048); my $keyidx = $rsa->get_public_key_string() if defined $rsa; $keyidx = sha512_hex($keyidx,""); $keyidx = substr($keyidx,0,6);
Basically (as already mentioned earlier) he's using the first 6 characters of the hex encoded hash of the hex encoded RSA public key string. What could possibly go wrong?
Another issue with the above code is that it would generate a keyid from undef if RSA key generation fails for some reason. And it would store it anyway.
Another problem is, that all key material is being stored on disk without permission setting or checking. So the script will use the current umask, which would be 0644 for most users, therefore leaving the keys open to fetch for other users of the system.
There seems to be no key expire mechanism as well. Once generated a key will be used forever. At least in theory, since the RSA keys are not used anyway as mentioned above.
Other Oddities
Despite being a tool for encrypted radio communication the script contains code for Twitter publishing (with hardcoded API keys but they can be changed though), it fetches RSS feeds from various websites (hardcoded URIs of course), e.g. from NY Times.
But it supports using a TOR proxy after all.
Conclusion
By just using a mobile phone the user can communicate more secure via radios signals. Since every encryption is being done with the same hardcoded key, it is completely useless. If the author(s) fix at least the hardcoded key and random number generation issue, then the tool could have a future. See Update below!
Update 2016-10-04:
After someone responded to some of the issues in a github issue and said, that my finding that AirChat uses hardcoded keys is wrong, I did some further tests:
#!/usr/bin/perl
use Crypt::CBC;
use MIME::Base64;
my $k1 = "eins";
my $k2 = "zwei";
my $cl = "hallo";
my $c1 = Crypt::CBC->new({ key => $k1 });
$c1->{passphrase} = $k2;
my $en = $c1->encrypt($cl);
my $c2 = Crypt::CBC->new({ key => $k2 });
printf "clear: %s decr: %s",
encode_base64($cl),
encode_base64($c2->decrypt($en));
This prints:
% ./t.pl clear: aGFsbG8= decr: aGFsbG8=So, as it seems, if you set the HASH parameter
Crypt::CBC::passphrase after the object has been initialized with a key parameter, the latter will be used by the module.
Therefore my conclusion that the tool is insecure because of hardcoded keys was wrong. It might still be insecure because of other reasons though, but this is not part of this update. However, it is confusing for the casual reader to see those hardcoded (but, as I now found, unused) keys in the code. In fact I only made the review in the first place because of this.