Posts on tag: source
Table of contents
DigiProof: Digitales Testament
Ich hatte mir zu dem Thema digitales Erbe ja schon mal vor einiger Zeit Gedanken gemacht. Inzwischen hatte ich die glorreiche Idee, dafür eine Software zu schreiben, mit der man so ein Testament komfortabel anlegen und verwalten kann. Das "glorreich" klingt etwas ironisch, was (leider) Absicht ist.
Am Anfang hatte ich mich gefragt, wie man so eine Software am besten schreiben kann, so dass sie von möglichst vielen Leuten benutzt werden kann. Es gäbe da diverse Varianten, die mir eingefallen sind:
- Als native Binary. Das heisst, z.b. in C++ geschrieben und für diverse Plattformen native übersetzt, also als Linux ELF Binary, Windows Exe oder MacOSX App. Die Schwierigkeit - für mich jedenfalls - dabei ist, ein portables GUI Programm zu schreiben. Ich habe mit native GUIs wenig Erfahrung, am ehesten noch mit Perl-TK, was aber für so ein Projekt nicht in Frage käme. Hinzu kommt, dass es für die diversen Systeme die verschiedensten Installationsmethoden gibt. Da ist man jahrelang am rumfrickeln, bis man wirklich die wichtigsten Plattformen untersützt. Also so eher nicht.
- Als ausfüllbares Dokument. Hier müsste man sich nicht mit irgendwelchen Softwareinstallationen und Portabilität herumschlagen. Allerdings gibt es kein Dokumentenformat, das Formularfelder über alle Plattformen zuverlässig unterstützt. PDF käme dem noch am nähesten, aber unter Unixsystemen ist der Support eher bescheiden. Viel Ahnung hab ich davon auch nicht. Und die Datenpflege in so einem ausgefüllten Formular stelle ich mir auch eher eklig vor. Auch gestrichen.
- Als Webservice. Das klingt zunächst charmant und in dem Bereich habe ich das meiste Knowhow. Charmant ist das aber nur auf den ersten Blick. Denn ein Webservice bedeutet, dass die Zugangsdaten der Accounts, die man da einträgt, auf einem Server im Netz liegen würden. Und da der Benutzer da immer rankommen können muss, muss es am Server entschlüsselbar sein. Das ist alles der reinste Alptraum und gar nicht machbar. Vom NSA Problem mal ganz abgesehen.
- Als lokale Javascript App. Ich verwende ja nach wie vor TiddlyWiki, das ist so eine App. Das ist einfach eine HTML Datei, die man sich auf die lokale Platte packt, lokal via file:/// im Browser öffnet und dort Notizen einträgt. Das funktioniert wunderbar, ist portabel und erfordert beim Benutzer keine grossen Aktionen mit Softwaresetups etc. Das klang für mich nach DER tollen Idee.
Die letze Variante habe ich dann umgesetzt. Ich habe unter Verwendung von ember.js eine Javascript App erstellt, mit der man ein digitales Testament erstellen und ausdrucken kann. Die App funktioniert ganz hervorragend, ich hab sie sogar im IE zum Laufen gekriegt.
Im Lauf der Entwicklung hat sich dann jedoch herausgestellt, dass ich da wohl etwas vorschnell und unüberlegt entschieden hatte. Ein Bekannter hatte die Problematik gut auf den Punkt gebracht: Was? Javascript? Und DA soll ich meine ganzen Zugangsdaten eintragen? NEVER EVER! Und er hatte Recht: klar, lokal im Browser geöffnet kann das Teil theoretisch nicht aufs Internet zugreifen und selbstverständlich habe ich auch nicht so eine Funktionalität eingebaut. Nur wer soll mir das glauben? Angesichts der aktuellen Ereignisse um die NSA ist ja vor allem eines sonnenklar: Vertrauen war einmal. Denn ich hatte eigentlich ursprünglich vor, die Idee zu Geld zu machen, sprich: die Software zu verkaufen oder sowas.
Aus dem Vertrauensproblem ergibt sich zwangsweise, dass ich die Software als OpenSource veröffentlichen muss. Dazu gibt es keine Alternative. Unbeteiligte müssen in der Lage sein, anhand des Source zu beurteilen, ob meine Aussagen über die Software stimmen. Ich kann die Software freilich unter die GPL stellen UND trotzdem dafür Geld verlangen. Ich vermute aber mal ganz vorsichtig, dass das wahrscheinlich kein erwähnenswertes Geschäft werden wird, da sich ja jedermann den Source auch einfach ziehen kann. Und da es Javascript ist, muss man da auch nichts compilieren oder so. Runterladen, im Browser aufmachen, gut ist.
So. Das ist der Stand der Dinge. Ich habe nun also die Ehre, die Software hier an dieser Stelle als BETA zu veröffentlichen. Man kann die vorerst testweise benutzen und ausprobieren, bis ich mir überlegt habe, wie es damit letztlich weitergeht.
Hier ein paar Screenshots von dem Tool:
So sieht der Hauptscreen aus: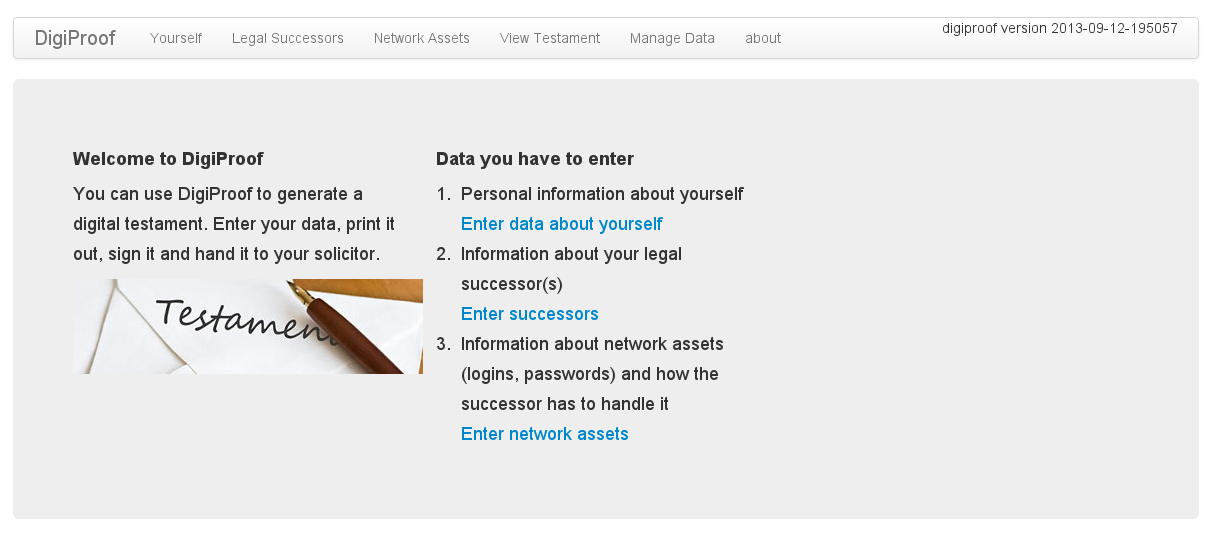
Man muss einige persönliche Angaben machen: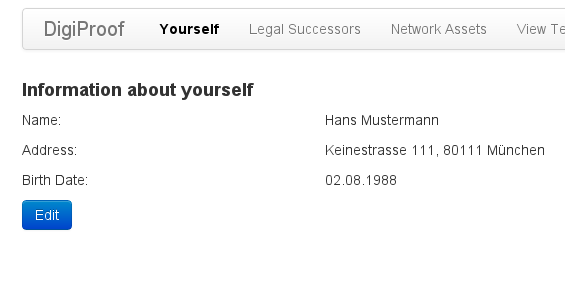
Hier wird ein Erbe eingegeben: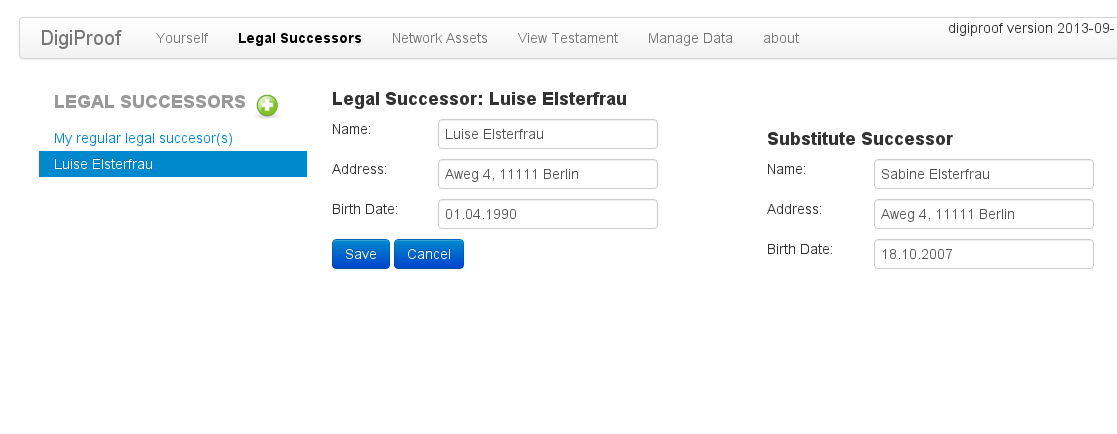
Und hier die Eingabe der Daten für einen Account, den zuständigen Erben und was der damit machen soll: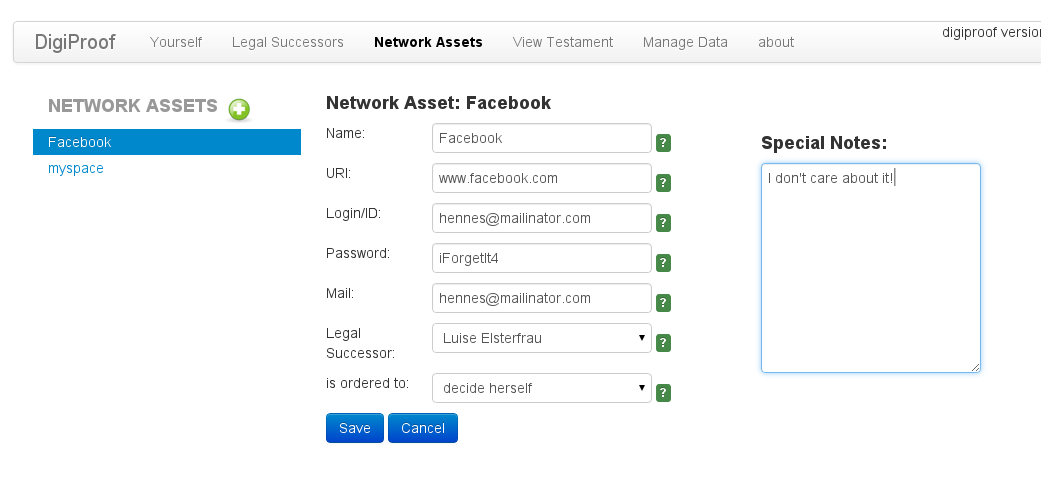
So sieht es nach der Eingabe aus: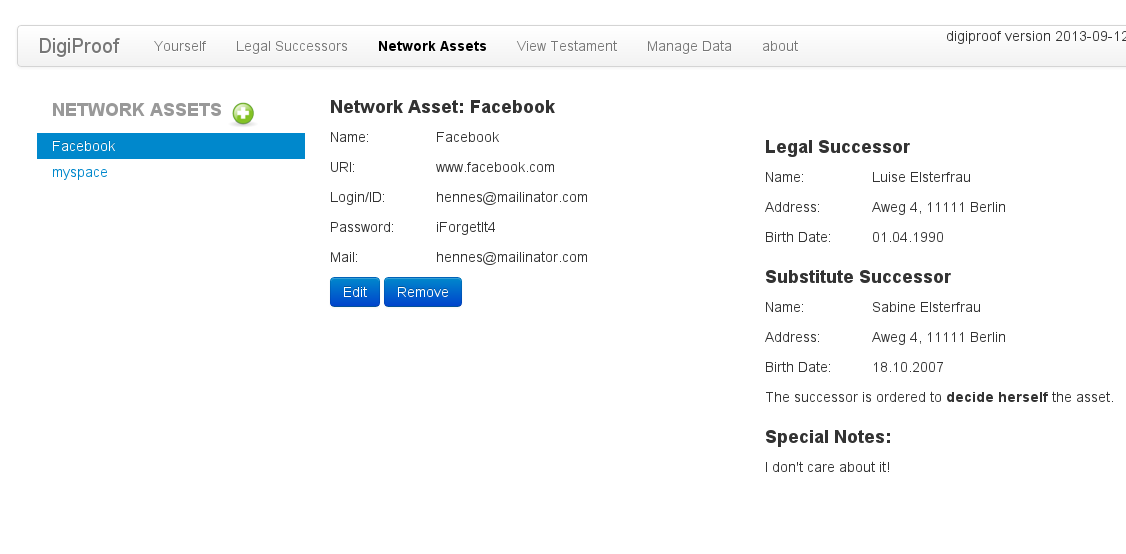
Das ist das fertig generierte und ausgedruckte Testament: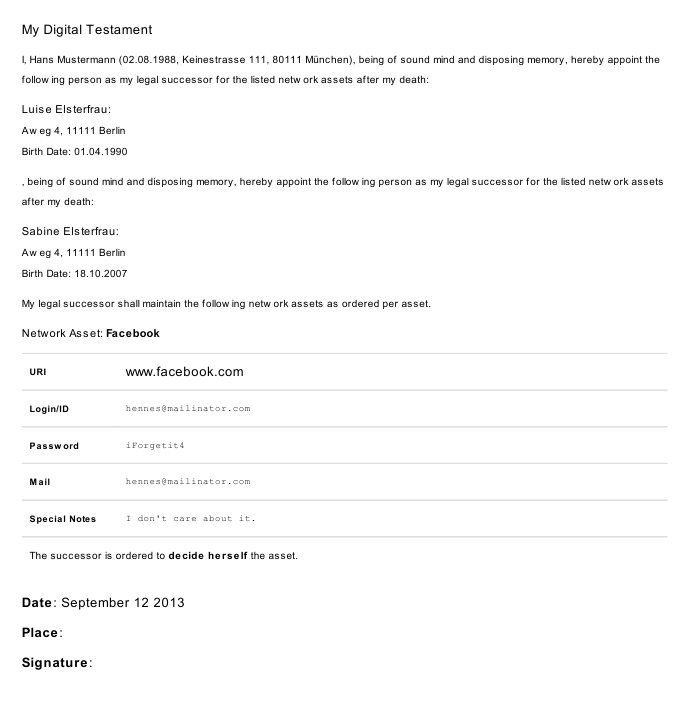
Hier auch nochmal als PDF: Beispiel Testament Ausdruck (PDF)
Man kann die Daten verschlüsselt exportieren: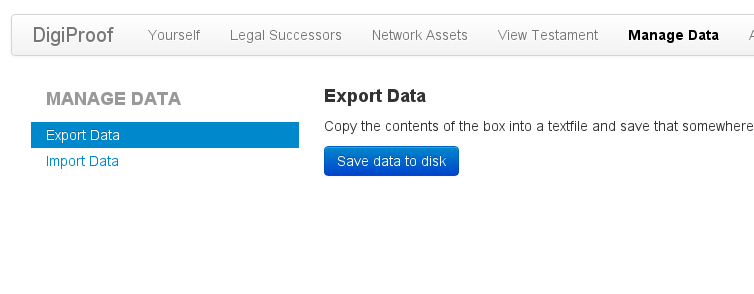
Und natürlich später wieder importieren: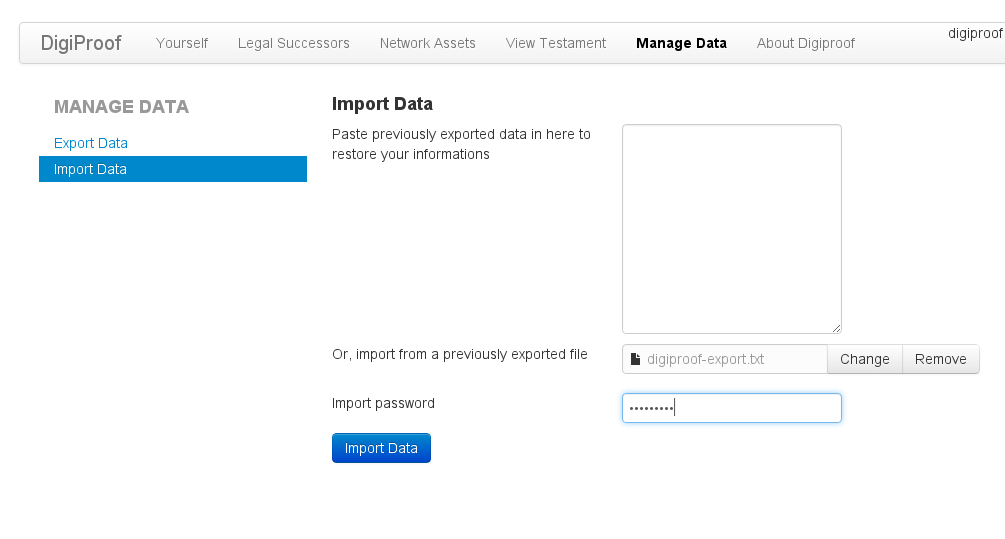
Der Export sieht so aus:
Den Source der aktuellen BETA 2013-09-11-232202 gibt es bei Github.
Hier in Kurzform eine Featureliste:
- in Javascript/HTML/CSS geschrieben, plattformunabhängig
- Daten werden nur temporär und nur lokal gespeichert, es wird nichts irgendwo hochgeladen
- man kann beliebige Accounts anlegen, pro Account die Zugangsdaten, den Erben und was damit zu tun ist
- man kann ausserdem beliebig viele Erben anlegen, pro Erben auch einen Vertreter/Ersatz
- das Anlegen von Erben ist optional, per Default würden dann die normalen Erben Rechtsnachfolger (also die, die durch Testament oder gesetzliche Erbfolge erben)
- das Testament kann man ausdrucken, pro Erbe wird extra ausgegeben, so dass ein Notar jedem Erben getrennte Dokumente aushändigen kann
- man kann die Daten verschlüsselt exportieren (Verschlüsselt mit einem 32fach mit SHA256 Hash aus einem Passwort mit AES256 im CBC Mode, mit einem Authentication MAC SHA512) und später wieder importieren.
- Unterstützung für Mehrsprachigkeit, derzeit deutsch und englisch (orientiert sich nach den Browsereinstellungen), hier mal ein Screenshot mit deutscher Sprache.
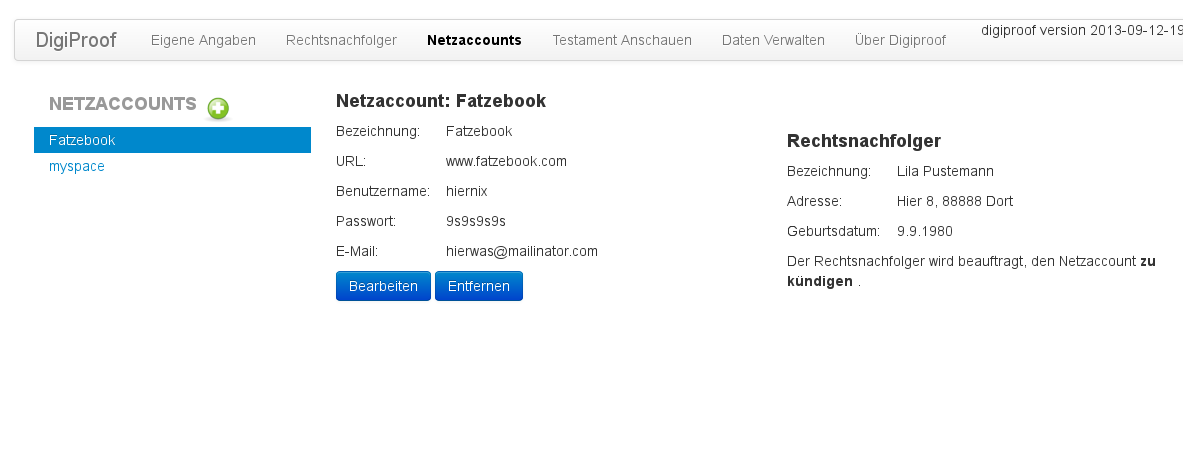{kind=link}
Zu guter Letzt ein Hinweis: Benutzung auf eigene Gefahr! Ich übernehme keine Gewähr für entstandene Schäden!
Probleme mit note und Crypt::PWSafe3 1.08
Mein Perlmodul Crypt::PWSafe3 ist ein Interface zur Datenbank des Passwortmanagers Password Safe, das ich vor geraumer Zeit entwickelt habe. Das Notizverwaltungsscript note - ebenfalls von mir - hat dafür ein Backendmodul bekommen, so dass man mit note auf PasswordSafe Dateien zugreifen kann.
Mit Version 1.08 des Crypt::PWSafe3 Moduls gab es aber ein Problem, wenn man note gestartet hatte, erschien nach der Passworteingabe diese Meldung:
notedb seems to be encrypted!
Ursache dafür war ein Bug in Crypt::PWSafe 1.08, eigentlich sogar auch noch einer im note. Der Bug ist - vorsichtig ausgedrückt - eklig. Eigentlich handelt es sich bei dem Modul um eine Portierung eines Pythonmoduls. Die Verschlüsselung der PasswordSafe Datenbank ist nicht gerade unkompliziert und anhand des vorhandenen Pythonmoduls hatte ich eine Vorlage, wie man das implementieren kann.
Natürlich gibt es diverse Unterschiede zwischen Python und Perl, einer davon sind Formatstrings, die von den pack() und unpack() Routinen akzeptiert werden. Diese Routinen kann man verwenden, um zum Beispiel aus binären Daten typisierte Werte zu extrahieren (z.b. aus einer Bytefolge eine Fliesspunktzahl). Das Datenbankformat von PasswordSafe schreibt nun für alle Felder Little Endian Bytereihenfolge vor, was beim Ent- und Verschlüsseln natürlich berücksichtigt werden muss.
Die Formatstrings von pack() und unpack() in Python bieten samt und sonders entsprechende Flags an, z.b. "L<4" extrahiert eine 4-Byte-Long-Zahl im little endian Bytereihenfolge. In der alten Version meines Moduls (1.04) hatte ich diese Flags noch nicht verwendet. Das war für mich auch kein Problem, da ich nur little endian Maschinen zur Verfügung hatte, also funktionierte alles. Portabel ist aber was anders. Also habe ich das bei 1.08 geändert und die endian Flags in den entsprechenden Routinen eingebaut.
Und hier haben wir nun das Problem: Der Formatstring für Hexwerte "H*" bietet in Python ebenfalls den little endian Flag, in Perl aber nicht! Ich stand also vor einem Problem, das ich gelöst habe, indem ich einfach "H*" durch "L<4" ersetzt habe. Die Ent- und Verschlüsselung funktionierte immer noch wie vorher und mit der Lösung war das Modul nun endlich vollständig portabel.
Der Haken an der Sache war, dass man natürlich von "L<4" einen Wert in der korrekten Grösse (16 Byte) zurück bekommt, aber keinen Hexstring, sondern eine Zahl. Modulintern war das völlig redundant, da an der Stelle sowieso nur mit Zahlen hantiert wird. Das war auch der Grund, weswegen ich das - wohlwissend um den Umstand - so gelassen habe.
Zum Problem wurde das ganze erst im Zusammenspiel mit note. Note ist sehr alt. 15 Jahre werden das jetzt schon sein, seit es das gibt, oder mehr. Müsste ich mal nachschauen. Jedenfalls hat jeder Eintrag im Note eine ID, d.h. eine Nummer. Über diese ID wird der Eintrag adressiert. Also mit dem Befehl "e 18" bearbeitet man den Eintrag 18. Diesen Umstand berücksichtigen sämtliche Speicherbackends von Note, von denen es mittlerweile eine Reihe gibt, die aber samt und sonders proprietär sind. Das PasswordSafe-Backend ist das erste und einzige offene Backend und dessen Format ist vorgegeben. Und dieses Format kennt eine solche Nomenklatur mit numerierten IDs pro Eintrag nicht. Statt dessen werden in PasswordSafe die Einträge mit einer UUID adressiert. Das ist sehr elegant aber für mich als Noteautor wenig hilfreich.
Gelöst habe ich das, indem ich im Backendmodul eine Routine eingebaut habe, die aus den UUIDs einigermaßen kleine Zahlen generiert. Der Algorithmus ist primitiv, aber er erzeugt für die gleiche UUID immer die gleiche Zahl. Somit sind Note-Einträge eindeutig adressierbar und die Inkompatibilität war gelöst. Allerdings basiert die Routine darauf, dass die UUID als Hexstring vorliegt. Jedoch war das bei Crypt::PWSafe3 ab 1.08 nicht mehr der Fall, hatte ich dort ja für Hexstrings auf "L<4" umgestellt.
Die Routine hat daher nicht mehr funktioniert und immer IDs erzeugt, die bei 1 anfingen und einfach fortliefen. Hier kommt der zweite Bug zu Tage. An sich wäre das kein Problem: solange die IDs reproduzierbar und eindeutig sind, ist ja alles gut. Aber im Note ist eine Abfrage eingebaut, die prüft, ob auf eine verschlüsselte Datei zugegriffen wurde und die Entschlüsselung funktioniert hat, bzw. ob dies bei abgeschalteter Verschlüsselung geschah. Dazu nimmt sich Note den Eintrag mit der ID 1 und guckt beim Datum, ob es mit einer zweistelligen Zahl beginnt.
Das funktioniert bei allen Backends, nicht aber mit Crypt::PWSafe3. Dazu muss man wissen, dass die Passwortabfrage aus Implementierungsgründen im Backend eingebaut ist und bei dem Backend also nicht die Abfrage aus Note selbst verwendet wird. Daher muss man in der Config bei Verwendung dieses Backends die Verschlüsselung abschalten, damit sich beide Abfragen nicht in die Quere kommen. Dadurch wird aber die erwähnte Prüfroutine aktiviert. Die oben zitierte Fehlermeldung kommt von da.
Bis Crypt::PWSafe3 1.08 war das nie ein Problem, weil die Routine, die aus den UUIDs die Note-IDs erzeugt hat, niemals eine ID 1 errechnet hatte. Das war nicht beabsichtigt, aber so wie ich den Algorithmus gestaltet hatte, wird da wohl nie eine 1 herauskommen. Daher kam die Prüffunktion im Note nie zum Zug, weil es keinen Eintrag mit der ID 1 kam, was Note dazu veranlasst hatte, weiterzumachen (in der Annahme, die Datenbank sei leer). Mit dem geänderten unpack() Format für Hexstrings auf "L<4" kam aber nun auf einmal eine ID 1 heraus. Und hier kommt der nächste Bug: Im Backendmodul NOTEDB::pwsafe3 wiederum konvertiere ich die verschiedenen Felder der Datenbank in Note-kompatible Werte. Das Datumsfeld habe ich aber falsch konvertiert, da wurde ein einfacher localtime() String zurück gegeben, der mit dem Tag begann (wie in "Mi 19 Jun 2013 19:16:22 CEST"). Da das Datum nicht mit einer zweistelligen Zahl begann, hat die Noteroutine den erwähnten Fehler geworfen, davon ausgehend, dass auf eine verschlüsselte Datenbank zugegriffen wurde, die nicht entschlüsselt wurde.
Ich habe daher nun in Version 1.10 von Crypt::PWSafe3 wieder auf "H*" umgestellt. Das wird zwar eventuell Schwierigkeiten auf big endian Architekturen geben (Solaris z.b.), aber sollte es dazu kommen, werde ich den Bugreport an die Perlentwickler weiterleiten, weil das dann in dem Fall nicht mein Fehler ist. Gleichzeitig habe ich auch noch das Backendmodul für Note upgedatet, welches jetzt korrekte Datumswerte zurückliefert (für den Fall, dass doch mal eine ID 1 heraus kommt).
In der neuen Note-Version (1.16) wird nun auch nicht mehr länger der Eintrag mit der ID 1 geprüft, sondern einfach der erste Eintrag, welche ID auch immer der haben mag.
Rechen-Captcha bei Kommentarfunktion
Ich habe heute in meinem Kommentarformular eine Captchafunktion eingebaut, weil immer mehr SPAM aufgeschlagen ist.  Man muss eine simple Rechenaufgabe lösen, damit der Kommentar angenommen wird. Kommentare sind bei mir zwar immer moderiert, deswegen nerven mich die täglichen Notifications über Kommentarspam trotzdem.
Man muss eine simple Rechenaufgabe lösen, damit der Kommentar angenommen wird. Kommentare sind bei mir zwar immer moderiert, deswegen nerven mich die täglichen Notifications über Kommentarspam trotzdem.
Das sollte daher nun vorbei sein.
Viagra, my ass!
Update 2013-03-22:
Bleibt spannend. Sind natürlich immer noch SPAMer unterwegs, die nun auch nicht mehr durchkommen. Aber nun kriegen die alle einen HTTP 500 Error (d.h. Django stirbt da weg):- - [22/Mar/2013:04:51:39 +0100] "GET /blog/2011/04/24/2/neu-gemessen/ HTTP/1.1" 18957 200 "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.5) Gecko/2008120122 Firefox/3.0.5" "-" - - [22/Mar/2013:04:51:40 +0100] "POST /blog/2011/04/24/2/neu-gemessen/addcomment/ HTTP/1.1" 4719 500 "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.5) Gecko/2008120122 Firefox/3.0.5" "/blog/2011/04/24/2/neu-gemessen/"
Und das, obwohl meine ganze Maschinerie mit Exceptions funktioniert, die sollte dann eigenltich auch einen Django-Tod abfangen. Ich hab jetzt mal Error-Mailing aktiviert. Dann krieg ich nen Stacktrace und Environment gemailt, wenn das passiert. Ich bin ja gespannt wie Hulle, was die da eigentlich genau machen.
Update 2013-03-21:
So. Nachdem meine erste - primitive Variante - nicht ausreichend war, habe ich jetzt aufgerüstet. Ich bin den ausgezeichneten Ratschlägen von Web ohne Barrieren gefolgt und bin jetzt - denke ich - happy mit der Lösung.Im Einzelnen habe ich jetzt eine dreistufige Verteidigungslinie gegen SPAMer:
-
Stufe 1: Ein Timing Cookie
Das funktioniert wie folgt: wenn man ein einzelnes Blogposting aufruft, bekommt man einen Cookie mitgeliefert. Der Cookie beinhaltet den Timestamp des Zeitpunkts wo die URL aufgerufen wurde und eine Signatur aus Timestamp und einem Salt per SHA256.
Wenn das Kommentarformular gepostet wird, prüft Django eine Reihe von Dingen:- Der Cookie muss grundsätzlich vorhanden sein
- Der Cookie muss den Timestamp UND die Signatur beinhalten
- Die Signatur muss richtig sein!
- Der Timestamp darf nicht jünger als 10 Sekunden sein
-
Stufe 2: ein Honeypot Formularfeld
Im wesentlichen handelt es sich einfach um ein weiteres Formularfeld des Kommentarformulars. Dieses ist aber im normalen Browser nicht sichtbar. Dadurch wird es von einem Besucher auch nicht ausgefüllt und in dem Fall ist alles gut.
Wenn aber ein Bot dieses Feld ausfüllt, dann passieren zweierlei Dinge: zum einen kommt wieder das oben erwähnte Throttling zum Einsatz. Und zum anderen - sollte der SPAMer so geduldig sein - gibt es eine Fehlermeldung, das Formular sei falsch ausgefüllt (freilich ohne Hinweis, dass das Feld LEER sein muss, damit Django happy ist!). -
Stufe 3: Logikfragen als Captcha
Das hatte ich im Prinzip auch schon vorher. Nur da waren es noch einfache Rechenaufgaben. Jetzt sind es logische Fragen, die sich durch blindes maschinelles Übersetzen nicht so ohne weiteres beantworten lassen. Einfach mal hier unter diesem Posting die Frage anschauen, dann versteht man, was ich meine. Gerne öfter Reloaden - es gibt einen Pool an Fragen.
Update 2013-03-21:
Tja, scheint nicht wirklich zu helfen:- - [21/Mar/2013:07:21:24 +0100] "GET /blog/2012/08/06/85/her-name-2/ HTTP/1.0" 21352 200 "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:17.0) Gecko/20100101 Firefox/17.0" "/blog/2012/08/06/85/her-name-2/" - - [21/Mar/2013:07:21:26 +0100] "POST /blog/2012/08/06/85/her-name-2/addcomment/ HTTP/1.0" 17760 200 "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:17.0) Gecko/20100101 Firefox/17.0" "/blog/2012/08/06/85/her-name-2/"
War Kommentarspam. Na wunderbar. Ich frage mich, wie der das in 2 Sekunden hingekriegt hat!
How to reinvent the fucking wheel
Today I stumbled across this post by the iFixit makers. The interesting part can be found at the end of the post:
We are makers and we are fixers. Information on how to make, build, and fix things in the real world wants to be free. We want to help make that possible: this week, we’re making our publishing software, Dozuki, free for anyone to host open source, community-driven instruction manuals.
The site mentioned, "Dozuki" is actually not free, as can be read on the pricing page:
How does the free trial work?
Once your account representative has setup your site, you will have a 30 day Dozuki trial, completely free of charge. You won't be charged a cent if you cancel prior to the end of the free 30-day trial. After that, your plan will be billed once a month. It's easy to stop - or start - at any time.
So, I'm not sure, what they talk about in their post, but it's got nothing to do with opensource. But the thing, which annoys me is the fact, that they are reinventing the wheel for the thousandth time or so. Many others implemented opensource hosting platforms in the past. Of course for opensource software, not hardwar. But what's the difference? I don't see one from the philosophy perspective.
And why would one put their documentation to some remote site and not bundle it with the actual project? That's such a crappy idea. Nonsense. And then they babble about their proprietary format called the "Open Manual Format", which they describe as:
oManual is a simple, open XML-based standard for semantic, multimedia-rich procedural manuals.
Using XML to write a manual? You lose. No developer will do that. You write a README textfile. If you're oldschool you write a manpage. You maintain a webpage about the project where you describe it using HTML. Including images, videos, whatnot. You don't need such XML rubbish for this purpose.
From these things you can see, that many people of the so-called "open hardware movement" (or "makers" how they call themselfes often) don't have an opensource background. They never came in touch with opensource software. The don't know much about licensing (just take a look on the TOS on the Dozuki site). They just make the same errors as others of the opensource software community did before.
Sad.
Quick monitoring script for commandline using google graph
So, you need to setup a graph for something you maintain, for instance response time of a webserver, memory consumption of some process or open database handles. Fast.
You could use MRTG, if you've got it already running. But either way - to add a new graph there isn't really done fast. And what if you don't have MRTG? What about GNU Plot or Google Graph? Every tool like this needs handwork to be done before being able to produce usefull output. One needs more than the other.
Enter quickmon. This is a small script I wrote for the very purpose. It doesn't have any dependencies and therefore runs out-of-the-box. You supply it one or more shell commands and it generates a google graph page and a logfile where it maintains history. It is really not possible to create monitoring graphs any faster!
And as a plus, the tool itself doesn't require internet access. It can run anywhere, inside some protected DMZ or the like. Only the browser which is used to view the output page needs internet access to fetch the google graph JS-library. That's it.
So, first of all, grab a copy of the script from here.
Now, let's take a look at some examples:
quickmon.pl -n "google mx lookup responsetime" \
-t "google millisecs" \
-c "host -v -t MX google.com 8.8.8.8 | grep Received | awk '{print \$7}'" \
-l
In this example we monitor the response time of googles nameserver (when asked for its mx-record) in milliseconds. As you can see, there's one -t and one matching -c parameter. -t tells us what we are actually monitoring and -c is the shell command to be executed. In this example we're using host -v which prints the responsetime of a query in milliseconds. We fetch this value using the grep + awk after the pipe. Here's the output:
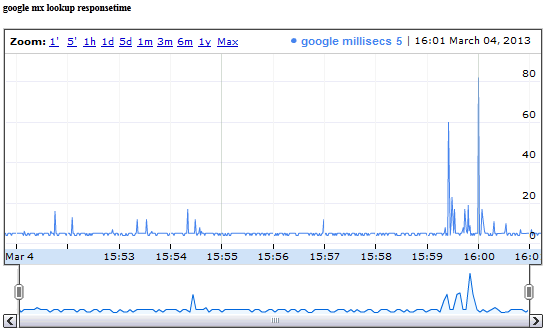
Here's another example:
quickmon.pl -n "google webserver response" \
-t "www.google.com" \
-c "wget -4 -q -O /dev/null www.google.com" \
-l
Note the difference to the previous one: we didn't put some grep + awk parser stuff into our shell command. If you do that, the script measures the time it takes to execute the command itself.
This is how it looks after some time:
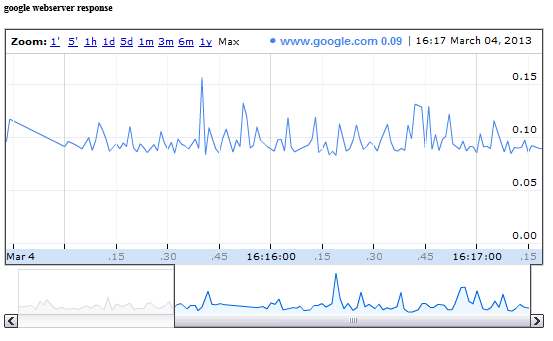
How about having multiple items in a graph? No problem, you can pass multiple -t and -c parameters to the script. However, be careful to have always one -t for every -c. And: order matters.
quickmon.pl -n "webserver comparision" \
-t "www.google.com" -c "wget -4 -q -O /dev/null www.google.com" \
-t "www.facebook.com" -c "wget -4 -q -O /dev/null www.facebook.com" \
-t "www.apple.com" -c "wget -4 -q -O /dev/null www.apple.com" \
-l
Ok, quite a long commandline. Watch the matching -t and -c parameters. And here's the output:
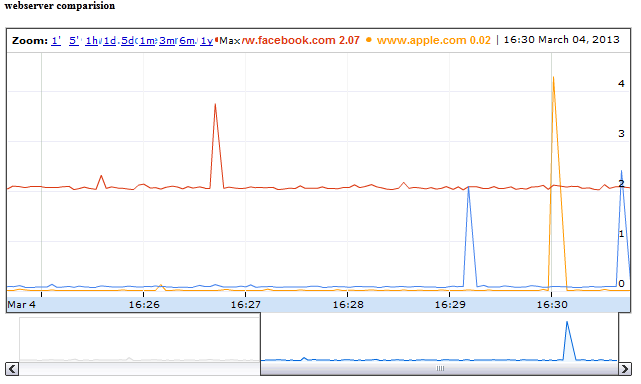
One last thing: You might have noticed the -l flag. If supplied, the script runs forever and executes the given commands once every second. That's enough for some quick graphing but sometimes you might need to create graphs for longer timescales, say some days or weeks. In such cases running once per second might be overkill. And executed this way, the script doesn't survive reboots. In such cases just add a cronjob, which executes the quickmon.pl script once every 5 minutes (or whatever you like) and leave the -l parameter. Example:
*/5 * * * * cd /home/user/tmp/ && /usr/local/bin/quickmon.pl -t "title" -c "command"
Beware the chdir call: quickmon.pl uses the current directory to write its logfile and the output page (index.html).
In case you want to take a look at a live sample, here you go: it is the webserver comparision described above, run every 5 minutes by cron.
Well. While this all might sound very cool, there's still one usecase where quickmon.pl could be too complicated. Let's recall: for every painted line in the output graph you have to provide a shell command which returns its value. What if you already have a source which returns such values all at once? Given the examples above it might look like we have to provide one -c parameter per value but each command has to split the same input source differently. That's odd. To say the least.
Take a look at this command output:
$ netstat -w 1 -I bge0 -q 1
input (bge0) output
packets errs idrops bytes packets errs bytes colls
9 0 0 828 8 0 9108 0
We've entered the netstat command which printed some stats about a specific network interface. Wouldn't it be good to feed quickmon directly with that output? The good news is: it's possible! Here's a quickmon call which catches some of those values - in and out bytes - to generate a graph from it:
while :; do netstat -w 1 -I bge0 -q 1 | egrep -v "(input|packets)"; done \
| quickmon.pl -t in-bytes -t out-bytes -p -n bge0 -f 3,6
There's a lot new stuff here, let's dig into it:
- We're calling the netstat command inside an infinite while loop, because otherwise it doesn't print to stdout but to our controlling terminal (which quickmon doesn't catch). This is freebsd specific. Behavior maybe different on other OSes.
- The egrep filters out the headings.
- We provide only 2 titles using -t, because we catch only field #3 and #6 (count starts from 0) by using the -f option.
- Option -p tells quickmon to watch a file. Since we didn't specify a filename, it uses STDIN, which is actually the output of our while loop.
And this is the output of the above after a while:
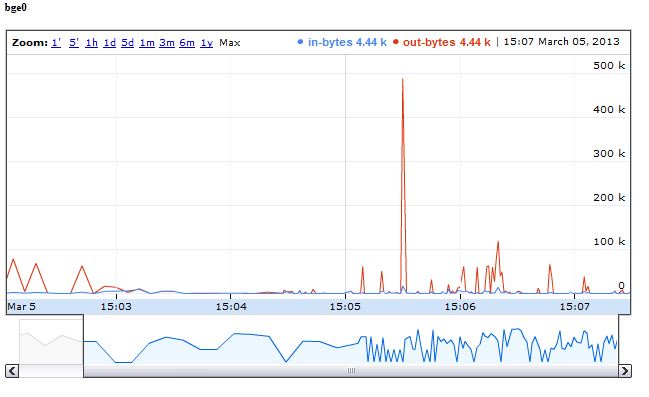
Nice, isn't it?
By default quickmon splits the input using whitespace. You might alter this behavior by supplying a different field-separator using the -F option.
Update 2015-10-18:
The script is now available on Github. The switch -l now has an optional parameter, the time in seconds to wait between loops, a float (i.e. .1 or 2.5 would be legal)Also, in pipe mode (-p) it's now possible to specify one title with a timestamp using format characters. So if your input file already contains a timestamp you can use that instead of generated ones.